Introducción
Estamos viendo un crecimiento en el uso y desarrollo de los modelos de lenguaje (LLMs) así como de sus multiples aplicaciones, que abarcan todo tipo de industrias. Pero toda esta revolución en los modelos de lenguaje no habría sido posible sin un nuevo tipo de datos que sirve de piedra angular en todos estos desarrollos: los embeddings. Y que ha llevado a la necesidad de desarrollar nuevas bases de datos para trabajar con ellos.
Los vector embeddings, son una manera de representar palabras y textos en forma de vector, que generamos a partir de modelos específicos de embedding. Estos datos vectoriales contienen información semántica clave para que la AI gane comprensión y mantenga una memoria a largo plazo en la cual basarse para ejecutar tareas complejas.
Los embeddings son generados por modelos de lenguaje y tienen muchos atributos o características, reflejados cada uno en un una dimensión distinta del vector, lo que hace que su representación sea complicada de manejar. En el contexto de AI y Machine Learning, estas características representan diferentes dimensiones de los datos que son esenciales para comprender patrones, relaciones y estructuras subyacentes.
Por eso necesitamos una base de datos especializada, diseñada específicamente para manejar este tipo de datos. Las bases de datos vectoriales como Pinecone cumplen con este requisito al ofrecer unas capacidades optimizadas para el almacenamiento y consulta de embeddings. Las bases de datos vectoriales combinan: las capacidades de una base de datos tradicional, que están ausentes en los índices vectoriales independientes (explicado más abajo); y la especialización para tratar con embeddings vectoriales, que las bases de datos escalares tradicionales no tienen.
El desafío de trabajar con datos vectoriales es que el rendimiento de las bases de datos escalares tradicionales se ve afectado por la complejidad y escala de este nuevo tipo de datos, lo que dificulta hacer búsquedas y realizar análisis en tiempo real. Ahí es donde entran en juego las bases de datos vectoriales: están diseñadas exclusivamente para manejar este tipo de datos y ofrecen el rendimiento, la escalabilidad y la flexibilidad que necesitas para aprovechar al máximo tus datos vectorizados o embeddings.
Con una base de datos vectorial, podemos agregar funciones avanzadas a nuestra AI, como búsqueda semántica de información o memoria a largo plazo, es decir, que nuestro modelo pueda trabajar con un contexto de conocimiento más amplio. El diagrama siguiente, que explicamos más abajo, nos ayuda a visualizar el papel de las bases de datos vectoriales en este tipo de aplicaciones:
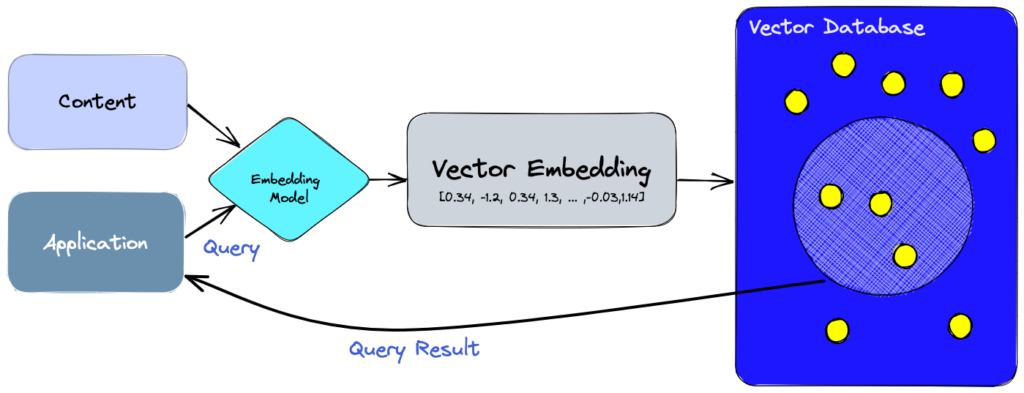
Primero, usamos un modelo de embedding para crear vector embeddings del contenido que queremos almacenar e indexar.
Luego, los vectores obtenidos en el paso anterior se insertan en la base de datos vectorial, con una referencia al contenido original.
Cuando un usuario quiere consultar la base de datos, usamos el mismo modelo de embedding para vectorizar la consulta y usamos la representación vectorial de la pregunta que hace el usuario para consultar la base de datos. De esta manera, identificamos aquellos vectores en la base de datos más próximos en significado a la consulta. Como hemos comentado antes, esos embeddings similares están asociados al contenido original que se utilizó para crearlos.
¿Cuál es la diferencia entre un índice vectorial y una base de datos vectorial?
La búsqueda vectorial, basada en índices vectoriales, ha sido utilizada por gigantes tecnológicos como Google y Amazon durante décadas. Se ha afirmado que es un motor significativo en clics, vistas y ventas en varias plataformas, ya que facilita la recomendación de opciones más afines al usuario. Y gracias a proyectos de código abierto como FAISS (Facebook AI Similarity Search), esta tecnología se ha vuelto más accesible.
En los últimos años, la búsqueda vectorial explotó en popularidad. Ha impulsado las ventas del comercio electrónico, potenciado la búsqueda de música y podcasts, e incluso recomendado tus próximos programas favoritos en plataformas de streaming. La búsqueda vectorial está en todas partes, y los índices vectoriales independientes como FAISS pueden mejorar significativamente la búsqueda y recuperación de embeddings vectoriales, pero carecen de capacidades que existen en cualquier base de datos.
Las bases de datos vectoriales, por otro lado, están construidas con el propósito de gestionar embeddings vectoriales, atacando las limitaciones de los índices vectoriales independientes. Estas limitaciones incluyen desafíos de escalabilidad, procesos de integración complejos, y la ausencia de actualizaciones en tiempo real y de medidas de seguridad integradas. De esta manera, la base vectorial no deja de ser una evolución del índice vectorial, augmentando las capacidades de este.
¿Cómo funciona una base de datos vectorial?
Todos tenemos una intuición sobre cómo funcionan las bases de datos tradicionales: almacenan texto, números y otros tipos de datos escalares en filas y columnas. Por otro lado, una base de datos vectorial opera sobre vectores, por lo que la forma en que se optimiza y consulta es bastante diferente.
En las bases de datos tradicionales, generalmente estamos consultando la base de datos por filas, donde el valor generalmente coincide exactamente con nuestra consulta. En las bases de datos vectoriales, aplicamos una métrica de similitud para encontrar el vector que está en la base de datos y que sea el más similar a nuestra consulta.
Una base de datos vectorial utiliza una combinación de diferentes algoritmos que participan en la búsqueda de lo que se llama Vecino Más Cercano Aproximado (Approximate Nearest Neighbor, ANN). Estos algoritmos optimizan la búsqueda a través de hashing, cuantificación o búsqueda basada en grafos.
Estos algoritmos se ensamblan en una tubería que proporciona una recuperación rápida y precisa de los vecinos del vector consultado (el que representa la pregunta o query). Dado que la base de datos vectorial proporciona resultados aproximados, los principales compromisos que consideramos son entre precisión y velocidad. Cuanto más preciso sea el resultado, más lenta será la consulta. Sin embargo, un buen sistema puede proporcionar una búsqueda ultra rápida con una precisión casi perfecta.
Aquí hay una pipeline común para una base de datos vectorial:

¿Cómo podemos comenzar a usar Pinecone?
En lo que sigue del documento se muestra un ejemplo sencillo de cómo puede utilizarse una base de datos vectorial, con el propósito de mostrar cómo de fácil es empezar a aprovechar estos recursos. En esencia, lo que hacemos es enseñar primero cómo escribir sobre las base de datos y luego pasar a leer de la base de datos mediante una consulta. Para ello utilizamos primero Pinecone, que nos permite crear la base de datos vectorial; y luego Langchain, que nos facilita acceder a un modelo de Open AI para convertir en embeddings la consulta que queremos realizar a la base de datos.
Similarity Search
Implementaremos ahora un ejemplo sencillo en Python de Similarity Search, método que nos puede servir para enriquecer las preguntas y respuestas de un chatbot con datos actualizados.
Para empezar, debemos instalar las librerías que usaremos en este ejemplo:
!pip install -qU \\
langchain==0.0.162 \\
openai==0.27.7 \\
tiktoken==0.4.0 \\
"pinecone-client[grpc]"==2.2.1 \\
pinecone-datasets=='0.5.0rc11'
Preparación de Datos
El caso de uso de chatbot requiere que almacenemos información relevante (contexto que sirve de base para las respuestas del chatbot) dentro de la base de datos vectorial. Para que el chatbot pueda acceder a estos contextos los codificamos en forma de embeddings vectoriales. Una vez que estos embeddings están indexados, podemos usarlos primero para aumentar el conocimiento del chatbot a la hora de recibir consultas de los usuarios:
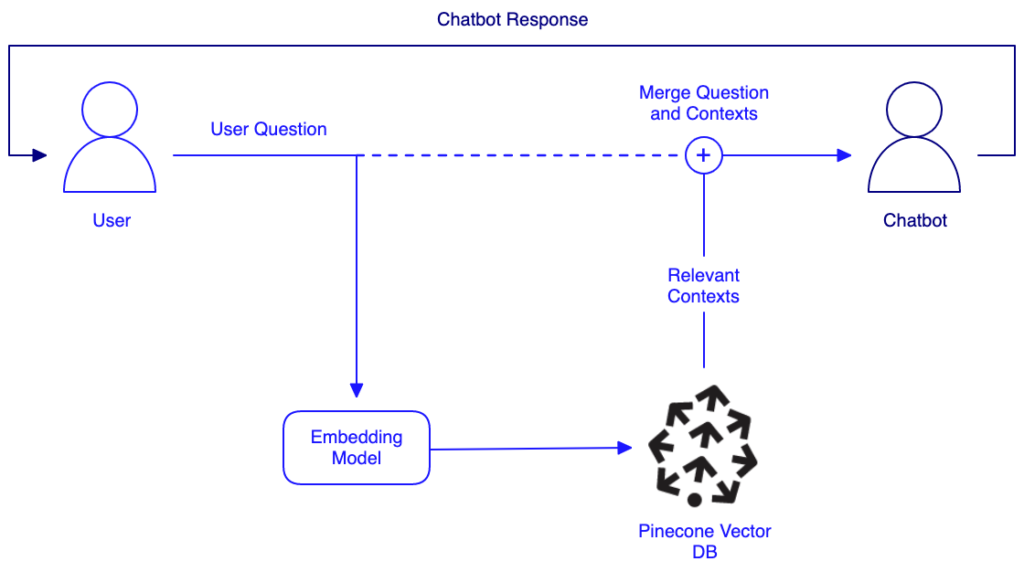
Descarga del Conjunto de Datos
Para poblar nuestra base de datos, descargaremos un conjunto de datos post-embedding de pinecone-datasets. Esto nos permite omitir el paso de embedding y el resto de pasos de preprocesamiento. Cuando trabajes con tu propio conjunto de datos, necesitarás realizar el embedding, un paso que ya hemos explicado en un blog anterior.
Pasamos entonces directamente a la acción:
import pinecone_datasets
dataset = pinecone_datasets.load_dataset('wikipedia-simple-text-embedding-ada-002')
dataset.head()
El comando “dataset.head()” nos devuelve por defecto los 5 primeros registros del dataset, que podemos ver a continuación:
id values sparse_values metadata blob
0 1-0 [-0.011254455894231796, -0.01698738895356655, ... None None {'chunk': 0, 'source': '<https://simple.wikiped>...
1 1-1 [-0.0015197008615359664, -0.007858820259571075... None None {'chunk': 1, 'source': '<https://simple.wikiped>...
2 1-2 [-0.009930099360644817, -0.012211072258651257,... None None {'chunk': 2, 'source': '<https://simple.wikiped>...
3 1-3 [-0.011600767262279987, -0.012608098797500134,... None None {'chunk': 3, 'source': '<https://simple.wikiped>...
4 1-4 [-0.026462381705641747, -0.016362832859158516,... None None {'chunk': 4, 'source': '<https://simple.wikiped>...
Como se puede ver en el output anterior, el contenido de una base de datos vectorial no es fácilmente interpretable. Cada uno de los registros mostrados arriba corresponde a la representación vectorial de un artículo de Wikipedia.
Un pinecone-dataset siempre contiene los siguientes campos: id, values, sparse_values, metadata y blob. Todo lo que necesitamos son los IDs, los embeddings vectoriales (almacenados en values) y algunos metadatos (que en realidad están almacenados en blob).
Creación de un Índice
Un índice es la unidad básica para trabajar con datos vectoriales en Pinecone. Nos permite guardar vectores, hacer queries de los vectores que almacena y realizar operaciones sobre estos vectores.
A continuación mostramos la creación de un índice con unos sencillos pasos:
Para crear nuestra base de datos vectorial, primero necesitamos una clave API gratuita de Pinecone. Después de registrarnos para conseguir esta API key y acceder a ella, la inicializamos y nos conectamos a ella con los siguientes comandos:
index_name = 'chatbot-onboarding'
index = pinecone.GRPCIndex(index_name)
# esperamos un momento para que el índice esté completamente inicializado
time.sleep(1)
index.describe_index_stats()
Después de los pasos anteriores obtenemos el siguiente output:
{'dimension': 1536,
'index_fullness': 0.0,
'namespaces': {},
'total_vector_count': 0}
Deberíamos ver que el nuevo índice de Pinecone está vació, tiene un total_vector_count de 0, ya que aún no hemos añadido ningún vector.
Ahora cargamos datos vectoriales en el índice antes creado:
index.upsert_from_dataframe(dataset.documents, batch_size=100)
Ahora que ya tenemos todo el contenido indexado, con el siguiente comando comprobamos que el índice ya no está vacío:
index.describe_index_stats()
Y obtenemos el siguiente output:
{'dimension': 1536,
'index_fullness': 0.1,
'namespaces': {'': {'vector_count': 30000}},
'total_vector_count': 30000}
Una vez “escrita” nuestra base de datos vectorial en Pinecone, vamos a ver como podemos usar esta información vectorial y traducirla a un formato que podamos leer.
Querying y lectura de datos
Ahora que hemos construido nuestra base de datos vectorial con Pinecone, podemos utilizar la librería LangChain para convertir en embeddings la consulta que queremos hacer a la base de datos . Necesitamos inicializar distintos objectos en Langchain que nos van a permitir trabajar con este tipo de datos, entre ellos un vector store, el cual se conecta a Pinecone y accede a sus vectores, realiza operaciones sobre los vectores y traduce el resultado a texto.
Para trabajar con LangChain, primero inicializamos el vector store:
from langchain.vectorstores import Pinecone
text_field = "text"
# volvemos al índice normal para langchain
index = pinecone.Index(index_name)
vectorstore = Pinecone(
index, embed.embed_query, text_field
)Una vez inicializado, podemos pasar a consultar el vector store directamente utilizando vectorstore.similarity_search:
query = "¿quién fue Benito Mussolini?"
vectorstore.similarity_search(
query, # nuestra consulta de búsqueda
k=3 # devuelve los 3 documentos más relevantes
)Y obtenemos el siguiente output
[Document(page_content='Benito Amilcare Andrea Mussolini KSMOM GCTE (29 July 1883 – 28 April 1945) was an Italian politician and journalist. He was also the Prime Minister of Italy from 1922 until 1943. He was the leader of the National Fascist Party.\\n\\nBiography\\n\\nEarly life\\nBenito Mussolini was named after Benito Juarez, a Mexican opponent of the political power of the Roman Catholic Church, by his anticlerical (a person who opposes the political interference of the Roman Catholic Church in secular affairs) father. Mussolini\\'s father was a blacksmith. Before being involved in politics, Mussolini was a newspaper editor (where he learned all his propaganda skills) and elementary school teacher.\\n\\nAt first, Mussolini was a socialist, but when he wanted Italy to join the First World War, he was thrown out of the socialist party. He \\'invented\\' a new ideology, Fascism, much out of Nationalist\\xa0and Conservative views.\\n\\nRise to power and becoming dictator\\nIn 1922, he took power by having a large group of men, "Black Shirts," march on Rome and threaten to take over the government. King Vittorio Emanuele III gave in, allowed him to form a government, and made him prime minister. In the following five years, he gained power, and in 1927 created the OVRA, his personal secret police force. Using the agency to arrest, scare, or murder people against his regime, Mussolini was dictator\\xa0of Italy by the end of 1927. Only the King and his own Fascist party could challenge his power.', metadata={'chunk': 0.0, 'source': '<https://simple.wikipedia.org/wiki/Benito%20Mussolini>', 'title': 'Benito Mussolini', 'wiki-id': '6754'}),
Document(page_content='Fascism as practiced by Mussolini\\nMussolini\\'s form of Fascism, "Italian Fascism"- unlike Nazism, the racist ideology that Adolf Hitler followed- was different and less destructive than Hitler\\'s. Although a believer in the superiority of the Italian nation and national unity, Mussolini, unlike Hitler, is quoted "Race? It is a feeling, not a reality. Nothing will ever make me believe that biologically pure races can be shown to exist today".\\n\\nMussolini wanted Italy to become a new Roman Empire. In 1923, he attacked the island of Corfu, and in 1924, he occupied the city state of Fiume. In 1935, he attacked the African country Abyssinia (now called Ethiopia). His forces occupied it in 1936. Italy was thrown out of the League of Nations because of this aggression. In 1939, he occupied the country Albania. In 1936, Mussolini signed an alliance with Adolf Hitler, the dictator of Germany.\\n\\nFall from power and death\\nIn 1940, he sent Italy into the Second World War on the side of the Axis countries. Mussolini attacked Greece, but he failed to conquer it. In 1943, the Allies landed in Southern Italy. The Fascist party and King Vittorio Emanuel III deposed Mussolini and put him in jail, but he was set free by the Germans, who made him ruler of the Italian Social Republic puppet state which was in a small part of Central Italy. When the war was almost over, Mussolini tried to escape to Switzerland with his mistress, Clara Petacci, but they were both captured and shot by partisans. Mussolini\\'s dead body was hanged upside-down, together with his mistress and some of Mussolini\\'s helpers, on a pole at a gas station in the village of Millan, which is near the border between Italy and Switzerland.', metadata={'chunk': 1.0, 'source': '<https://simple.wikipedia.org/wiki/Benito%20Mussolini>', 'title': 'Benito Mussolini', 'wiki-id': '6754'}),
Document(page_content='Veneto was made part of Italy in 1866 after a war with Austria. Italian soldiers won Latium in 1870. That was when they took away the Pope\\'s power. The Pope, who was angry, said that he was a prisoner to keep Catholic people from being active in politics. That was the year of Italian unification.\\n\\nItaly participated in World War I. It was an ally of Great Britain, France, and Russia against the Central Powers. Almost all of Italy\\'s fighting was on the Eastern border, near Austria. After the "Caporetto defeat", Italy thought they would lose the war. But, in 1918, the Central Powers surrendered. Italy gained the Trentino-South Tyrol, which once was owned by Austria.\\n\\nFascist Italy \\nIn 1922, a new Italian government started. It was ruled by Benito Mussolini, the leader of Fascism in Italy. He became head of government and dictator, calling himself "Il Duce" (which means "leader" in Italian). He became friends with German dictator Adolf Hitler. Germany, Japan, and Italy became the Axis Powers. In 1940, they entered World War II together against France, Great Britain, and later the Soviet Union. During the war, Italy controlled most of the Mediterranean Sea.', metadata={'chunk': 5.0, 'source': '<https://simple.wikipedia.org/wiki/Italy>', 'title': 'Italy', 'wiki-id': '363'})]
De este forma hemos partido de un conjunto de datos vectoriales, los hemos subido a Pinecone creando una nueva base de datos vectoriales y finalmente hemos realizado un Similarity Search sobre ellos usando Langchain, que a su vez ha traducido los vectores a texto.
Conclusion
El uso y desarrollo de modelos de lenguaje avanzados se ha crecido de forma exponencial. Nuevas aplicaciones surgen cada día y su adopción por industrias de todo tipo es cada vez mayor. Pero nada de esto sería posible sin un nuevo tipo de dato: los vector embeddings. En este artículo, hemos podido adentrarnos en el concepto de embeddings y las bases de datos diseñadas específicamente para trabajar con ellos.
Más allá de los conceptos teóricos, nos hemos puesto manos a la obra a trabajar con Pinecone, una de las bases de datos vectoriales más populares, y hemos podido ver lo sencillo que es trabajar a nivel vectorial con esta herramienta. Más allá del nuevo marco teórico sobre el que se ha asentado todo esta revolución, otra de las claves, incluso más importante, es lo sencillo que resulta trabajar con este tipo de datos y modelos. Esta accesibilidad es lo que permite una innovación constante dentro del campo, permitiendo que gente normal, sin necesidad de tener un background técnico importante, pueda ponerse manos a la obra probando e implementando sus propias ideas o soluciones.



