En este artículo queremos compartir cómo puedes usar “embeddings” para crear tu propia base de conocimiento privada. Es casi como tener un cerebro de IA que conoce las mejores prácticas de cómo opera tu empresa o el funcionamiento de tu vida personal y las utiliza para impulsar decisiones diarias.
Para lograr este objetivo, tenemos dos posibilidades. Puedes hacer un fine-tuning de un Large Language Model (LLM), o puedes aplicar un método muy útil llamado “Knowledge base embedding”. Ambos tienen utilidades diferentes.
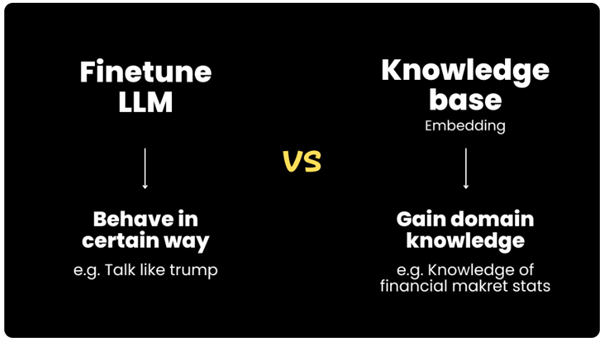
El “fine-tuning” de un LLM es útil cuando quieres que el LLM se comporte de cierta manera. Por ejemplo, si quieres digitalizar a alguien para que hable como Donald Trump, entonces es donde utilizarías el “fine-tuning”. Sin embargo, no es apto para recuperar datos y conocimientos muy específicos, y ahí es donde entra el “knowledge base embedding”. Este es particularmente útil cuando quieres que el LLM tenga conocimientos de dominio específicos, como el SOP (standard operating procedure) de tu empresa o algunos datos privados que estás guardando. Así que dado nuestro objetivo inicial, vamos a hablar sobre cómo usar este sistema.
¿Qué es el “Knowledge base embedding”?
“Knowledge base embedding” significa que cuando un usuario tiene una pregunta, en lugar de enviar su pregunta a los LLMs que no tienen idea de tus datos privados (e.g. documentos de tu empresa), intentarás buscar qué documentos relevantes se relacionan con las preguntas de estos usuarios.
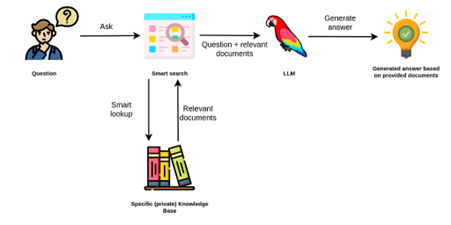
Por ejemplo, si un usuario pregunta cuál es el coste de tu producto para un equipo de tres personas, entonces el Knowledge base embedding intentará encontrar todo el contenido en tu página de precios y luego introducirá en un LLM tanto la consulta del usuario como el contenido de la página de precios, y dejará que se genere la respuesta basada en estos datos reales. A partir de este proceso, puede generar resultados mucho mejores que el modelo base o incluso el modelo con “fine-tuning”, gracias en gran parte a los “embeddings” y al almacenamiento de vectores. Estos ayudarán a encontrar información relevante en los documentos de tu empresa basándose en la consulta del usuario.
Explicaré ahora qué es un “embedding”, qué es una vector database, y cuáles son las diferencias entre ellos.
¿Qué es un “embedding”?
Un “embedding” es un tipo de “vector”. Probablemente acabo de decir dos palabras que no te transmiten mucho, pero en términos más simples, un “embedding” es como una representación de cuán cercano está cada punto de datos entre sí.
Por ejemplo, piensa en tener cuatro imágenes diferentes: dos tipos de árboles y dos tipos de animales. Puedes colocarlos en dos dimensiones de medición diferentes: una es si son un árbol o un animal, la otra es si son grandes o pequeños. Puedes medir cada imagen en esas dos dimensiones y ponerlas en el lugar correcto. A partir de ahí, podrás decir que una imagen de un árbol es muy diferente de una imagen de un ratón pequeño. Pero hay cierta similitud entre una foto de un árbol y una foto de un elefante porque ambos son grandes.
Este tipo de representación de cuán cercano está cada punto de datos, es básicamente un “embedding”. La diferencia es que el “embedding” no se mide solo en dos dimensiones sino en cientos o incluso miles de dimensiones diferentes. Los modelos de “embedding”, son como una máquina que puede convertir datos en una dimensión de “vector”, que es una lista de números en el lado derecho.
Estos modelos de “embedding” ya están preentrenados con muchos datos, por lo que han aprendido representaciones de cómo cada dos puntos de datos son similares entre sí. Por ejemplo, cuando presentas dos palabras como “king” y “queen” al modelo de “embedding” de OpenAI, probablemente ya ha aprendido que esas dos palabras están muy cerca y son similares en los datos de alfabetización en los que ha sido entrenado. Pero podrían estar bastante lejos en otras dimensiones. Por ejemplo, “King” podría ser un nombre, mientras que “Queen” no se usa comúnmente como un nombre.
Creo que captas mi punto. Estos modelos de “embedding” funcionan en diferentes tipos de medios como imagen, texto, audio e incluso videos. Esos son los “embeddings” y los modelos de “embedding”.
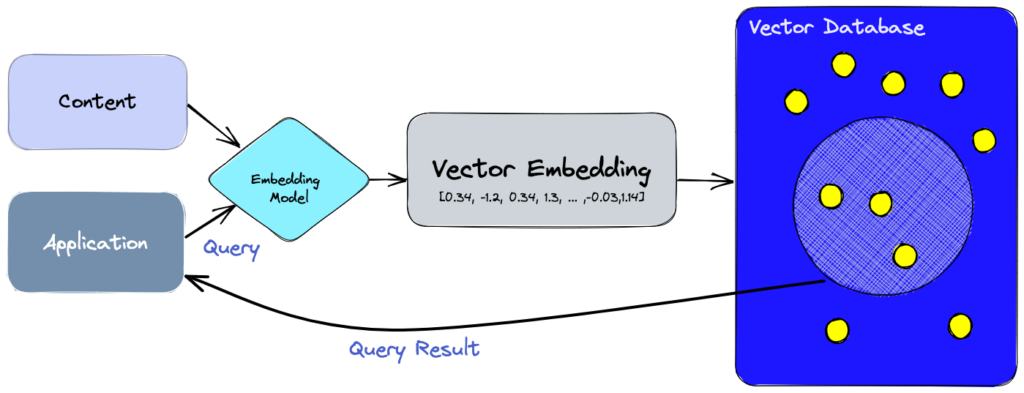
El otro concepto importante es el de vector database. El modelo de “embedding” convierte los datos en representaciones de “vector”, pero necesitas un lugar para almacenar todos esos datos en forma de vecrores y poder recuperarlos de manera muy efectiva para que puedas hacer cosas como búsquedas por similitud. Aquí es donde entran en juego vector databases como Chroma y Pinecone.
¿Qué casos de uso le podemos dar?
El “Knowledge based embedding” puede ser súper útil para la automatización de flujos de trabajo. Porque cuando piensas en cómo funciona hoy, la mayoría del conocimiento empresarial vive dentro de la cabeza de alguien, en lugar de ser compartido por todos en el equipo.
A menudo, es muy difícil articular cuáles son las mejores prácticas que hicieron las personas más destacadas pero que otras personas en el equipo no están haciendo. Esto genera muchos gastos generales para las empresas. Si una persona central en el equipo se va, entonces todo ese conocimiento desaparece. La forma en que las empresas resuelven este problema tradicionalmente es elaborando entre 40 y 100 páginas de documentos articulando cuál es el mejor proceso de ventas, una lista de diferentes SOP, y honestamente, nadie lee y a nadie le importan los documentos porque se vuelven obsoletos muy rápidamente. No hay un verdadero control de calidad sobre si las personas lo están utilizando en el proceso de actualización.
Pero por otro lado, con los “large language models” y la base de conocimientos con “embedding”, ¿qué tal si podemos tomar todos los correos electrónicos e interacciones con los clientes en un “embedding”, para que la próxima vez que cualquier persona, incluso un agente de soporte junior, reciba una queja u objeción de un cliente, pueda hacer automáticamente una búsqueda de similitud en la base de conocimientos para encontrar cuándo fue la última vez que ocurrió una queja similar de un cliente y cómo se comportaron los mejores empleados, y luego genere una respuesta basada en toda esa información.
Esto realmente puede cerrar las brechas entre los empleados de alto rendimiento y los empleados junior. Todo lo que necesitamos hacer es crear una base de conocimientos y dejar que el “large language model” aprenda y imite el comportamiento. Podríamos construir, por ejemplo, un sistema para redactar automáticamente correos electrónicos a clientes basados en las mejores prácticas de la empresa.
¿Cómo podemos construir este tipo de sistema?
Pasaremos ahora describir de forma más detallada como se construye y cómo funciona un sistema de “Knowledge based embedding”.
El proceso consiste en un método de dos pasos, Search-Ask, para permitir que los LLMs respondan preguntas utilizando tus datos privados como una biblioteca de texto de referencia.
- Search: busca en tu biblioteca secciones de texto relevantes
- Ask: utiliza las secciones de texto seleccionadas en el prompt que se introduce en el LLM para hacer una pregunta al modelo
Search
El texto puede buscarse de muchas formas. Por ejemplo,
- Búsqueda basada en léxico
- Búsqueda basada en gráficos
- Búsqueda basada en embeddings
En este momento, el método de búsqueda de texto más popular en el mundo de los LLMs es la búsqueda basada en embeddings. Los embedding representan palabras o fragmentos de texto de forma vectorial. La distancia entre los vectores mide el grado de cercanía entre las palabras. Las distancias pequeñas sugieren una alta relación y las distancias grandes sugieren una baja relación.
Los embeddings son simples de implementar y funcionan especialmente bien con preguntas, ya que las preguntas a menudo no se solapan léxicamente con sus respuestas. Puedes encontrarlos siendo utilizados en varios proyectos opensource populares como PrivateGPT, o en el plugin retrieval de ChatGPT recientemente anunciado.
Pero a pesar de su popularidad, debes considerar la búsqueda solo por embeddings como un punto de partida si quieres construir un sistema más avanzado. Los mejores sistemas de search deberían combinar múltiples métodos de búsqueda junto con funcionalidades extra como popularidad, recencia, historial de usuario, redundancia con resultados de búsqueda previos, datos de tasa de clics, etc.
El rendimiento de un sistema de Q&A retrieval también puede mejorarse con técnicas como HyDE, en las que las preguntas se transforman primero en respuestas hipotéticas antes de ser incorporadas. Eso significa que puedes usar el poder de los LLMs para preprocesar datos antes de generar los embeddings, para mejorar potencialmente los resultados de búsqueda. Otro ejemplo sería transformar automáticamente las preguntas en conjuntos de palabras clave o términos de búsqueda antes de hacer el embedding, lo que luego haría el trabajo de búsqueda más fácil y rápido.
Procedimiento completo
Específicamente, el procedimiento consta de los siguientes pasos:
- Preparar datos de búsqueda (ingestión de datos)
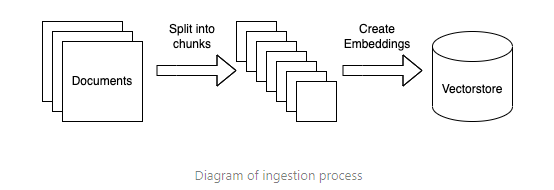
- Recolectar: Cargar fuentes de datos en texto
- Dividir: Los documentos se dividen en secciones cortas, mayormente autónomas para ser incorporadas. Esto es necesario porque los modelos de lenguaje generalmente tienen un límite en la cantidad de texto que pueden manejar.
- Embed: Esto implica crear un embedding numérico para cada fragmento de texto. Esto es necesario porque solo queremos seleccionar los fragmentos de texto más relevantes para una pregunta dada, y lo haremos encontrando los fragmentos más similares en el espacio de embeddings. Usa un modelo de embeddings de Hugging Face opensource si quieres ejecutar todo localmente. Una alternativa de API de pago sería utilizar los modelos de embeddings de OpenAI.
- Almacenar: Los embeddings se guardan. Para conjuntos de datos grandes, carga los embeddings en una base de datos vectorial. Las bases de datos vectoriales nos ayudan a encontrar los fragmentos más similares en el espacio de embeddings de forma rápida y eficiente. Usa Pincone o Chroma en caso de que quieras utilizar una solución local de código abierto.
2. Search (Consulta de datos)
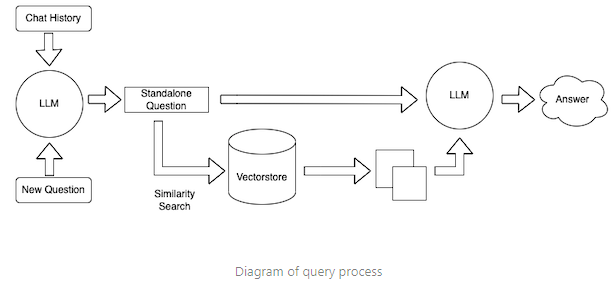
- Genera un embedding para la consulta usando tu modelo de embeddings.
- Busca documentos relevantes. Usando los embeddings, clasifica las secciones de texto por relevancia para la consulta.
3. Ask (generación del prompt)
- Inserta la pregunta y las secciones más relevantes en un mensaje al LLM
- Devuelve la respuesta del LLM


