Introducción
El crecimiento de la IA generativa está actualmente limitado por la capacidad disponible de computación. Estamos en un momento donde si utilizamos más datos y más capacidad de procesamiento podremos entrenar un modelo más grande (que tenga más parámetros) y generar mejores resultados. Normalmente, cualquier tipo de inversión tiene rendimientos marginales decrecientes, pero esto todavía no está ocurriendo con los modelos de inteligencia artificial y, como resultado, un factor determinante que está condicionando hoy la evolución de esta industria es simplemente el coste y los recursos disponibles para el entrenamiento e inferencia con modelos.
Aunque no conocemos los números exactos, la oferta de capacidad de computación más avanzada está muy limitada, y algunas fuentes indican que la demanda actual supera a la oferta por un factor de 10x. Así que en estos momentos podemos decir que el acceso a recursos de computación y su coste se ha convertido en un factor determinante para el éxito de cualquier proyecto que requiera entrenar, modificar (fine-tuning) y utilizar (inferencia) grandes modelos de IA.
En este artículo exploramos la elección entre infraestructuras de IA internas o externas, en función de las necesidades de cada startup; comparamos los costes variables de los proveedores de cloud computing; comentamos la creciente democratización de los modelos de IA; finalmente subrayamos la importancia de seleccionar el modelo adecuado para cada tarea específica y la emergencia de proveedores especializados de infraestructura de IA, como Together AI, que ofrecen una mayor especialización y eficiencia en tareas de IA.
Infraestructura externa vs. interna
Seamos sinceros: las GPUs son cool. Muchos ingenieros y founders técnicos tienen una inclinación hacia adquirir su propio hardware de IA, no sólo porque da un mayor control sobre el entrenamiento de modelos, sino porque hay algo divertido en aprovechar y jugar con el poder que te otorgan un gran número de GPUs.
La realidad, sin embargo, es que muchas startups no necesitan construir su propia infraestructura de IA desde el día uno. En cambio, los servicios que ofrecen plataformas como OpenAI, Hugging Face Model Hub, Replicate o Together AI permiten a las startups intentar encontrar product-market-fit rápidamente sin necesidad de gestionar la infraestructura subyacente. Podemos acceder a infraestructura para IA simplemente con llamadas a un API.
Estos servicios han evolucionado mucho en los últimos meses; lo que inicialmente podía ser un simple servicio para facilitar el testing de modelos de generación de imagen vía API, ha evolucionado a servicios mucho más verticalizados que permiten trabajar con un gran número de modelos open source y escalarlos en el cloud sin que luego sea un inconveniente integrarlos con tu stack vía API.
Los desarrolladores pueden lograr un control significativo sobre el rendimiento de los modelos mediante prompt engineering y el fine-tuning que se incluye en las API calls enviadas a estos proveedores de infraestructura AI. Los precios de estos servicios se basan en consumo, por lo que también suele ser más barato que desplegar, mantener y utilizar una infraestructura propia. Existen varias startups que han conseguido escalar de forma relevante basándose en estos servicios de infraestructura externa, como es el caso de PhotoRoom, una app de edición de fotos basada en IA con miles de usuarios por todo el mundo y que ya ha alcanzado $30 millones en ARR.
Por otro lado, algunas startups, especialmente aquellas que necesitan entrenar modelos fundacionales o construyen aplicaciones de IA muy verticalizadas con grandes volúmenes de datos, no pueden evitar ejecutar sus propios modelos directamente en GPUs propias. Ya sea porque el modelo es el producto, o porque se requiere un control detallado sobre el entrenamiento y/o la inferencia para lograr ciertas capacidades o para reducir el coste marginal a gran escala. En estos casos, gestionar infraestructura propia puede convertirse en una fuente de ventaja competitiva.
Costes de los proveedores de GPUs
Como acabamos de ver, tanto si eres una startup como una empresa más grande buscando integrar IA en tus productos y soluciones, el cloud es seguramente el lugar más adecuado donde tener tu infraestructura de IA. Tanto por el menor coste up-font, como por la capacidad de escalarlo up and down y evitarte las distracciones que implica montar y gestionar un data center.
Para poner un ejemplo, utilizando un proveedor como Lambda, podemos utilizar una GPU como una NVIDIA A100 de forma ininterrumpida durante casi un año por el mismo coste que adquirir esta misma GPU (sin considerar los costes asociados a la instalación o costes recurrentes como la electricidad) y pudiendo acceder a ella solo cuando necesitamos entrenar o correr nuevos modelos.
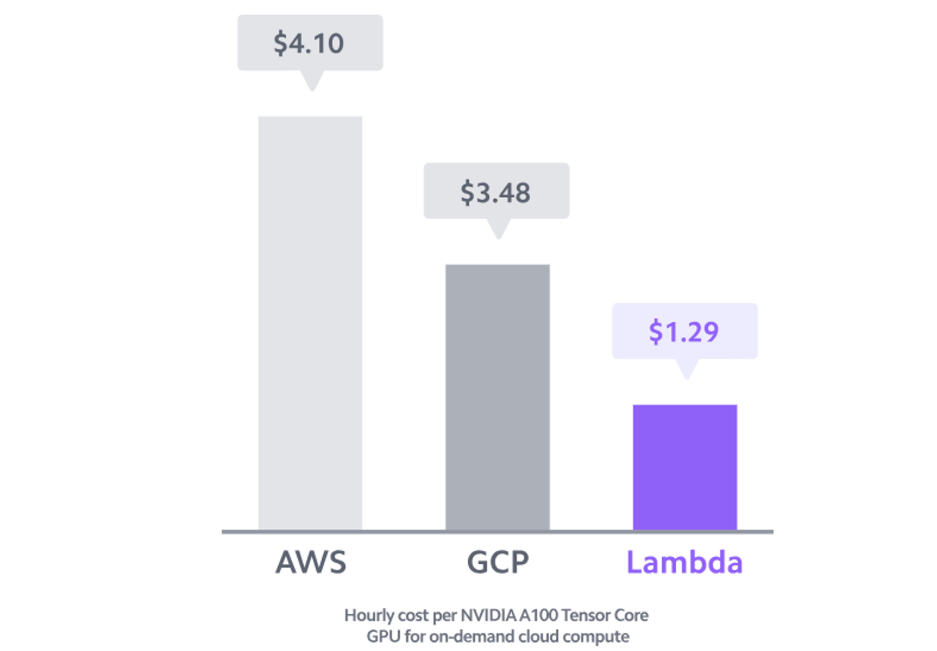
Esperamos por lo tanto que con el tiempo, la gran mayoría de startups utilicen proveedores cloud. Los players más establecidos como AWS, Microsoft Azure y Google Cloud Platform (GCP) ofrecen instancias de GPU, pero como ya hemos comentado, también están apareciendo nuevos proveedores enfocados específicamente en workloads de IA.
La tabla siguiente muestra los precios a mediados de 2023 que ofrecían los grandes cloud providers así como startups especializadas en AI infra . Esta información es solo indicativa, ya que se trata de una situación muy dinámica y las instancias varían considerablemente en términos de ancho de banda, costes de salida de datos, costes adicionales de CPU y red, y otros factores. Por ejemplo, Google requiere una instancia optimizada para poder correr los A100 de 40GB, lo que puede aumentar el coste en un 25%.
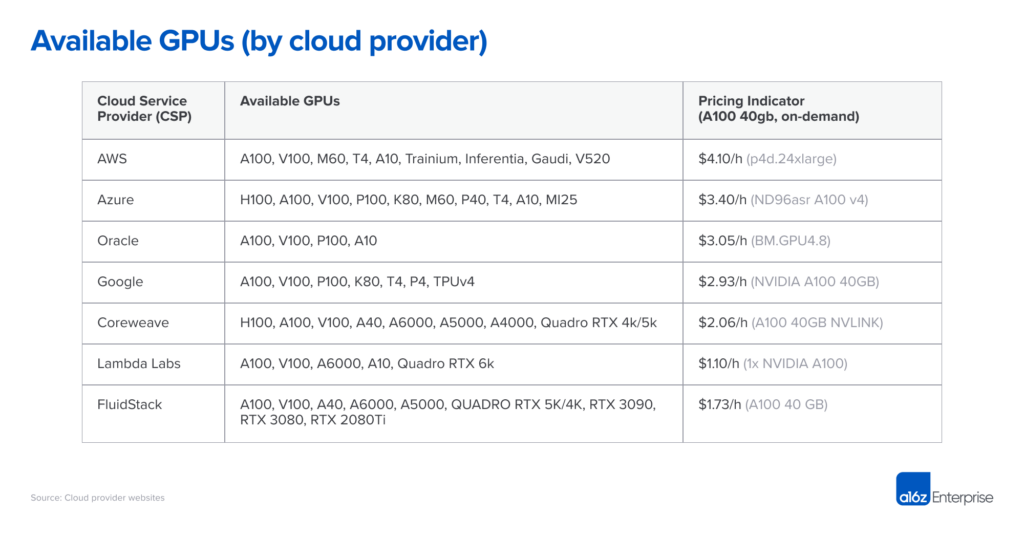
La capacidad de computación en hardware específico es un commodity, y sin tener demasiado contexto, esperaríamos precios bastante uniformes entre proveedores, pero no es el caso. Y aunque existen diferencias sustanciales de características entre los distintos cloud providers, son insuficientes para explicar porqué el precio de un NVIDIA A100 on-demand tenga una diferencia de casi 4x entre distintos proveedores.
En el extremo superior de la escala de precios, los grandes cloud providers cobran un premium basado en su reputación, fiabilidad probada y la necesidad de gestionar una amplia gama de workloads. Los proveedores más pequeños especializados en IA ofrecen precios más bajos, ya sea operando data centers construidos específicamente para ese fin (i.e., Coreweave) o arbitrando otras nubes (i.e., Lambda Labs).
En la práctica, la mayoría de los clientes más grandes negocian precios directamente con los grandes proveedores cloud, a menudo comprometiéndose a algún requisito de gasto mínimo así como compromisos de tiempo mínimos (actualmente de 1 a 3 años). Las diferencias de precios entre los distintos proveedores se reducen algo después de la negociación, pero igualmente el ranking en la tabla anterior se mantiene relativamente estable.
En cualquier caso, para las startups y empresas más pequeñas, si no tienen restricciones por parte de sus clientes, puede tener mucho más sentido trabajar con los nuevos proveedores cloud especializados en IA ya comentados (a los cuales podríamos añadir Modular o Anyscale) tanto para obtener precios más competitivos y evitar compromisos de gasto grandes, como por la ayuda y soporte que ofrecen a nivel de implementación, con equipos internos dedicados a ello.
Disponibilidad de GPUs y nuevos proveedores cloud
Las GPUs más potentes (i.e., las Nvidia A100 o H100) han escaseado durante los últimos 12 meses. Así que aunque ya hayas decidido qué proveedor cloud vas a usar, eso no significa que puedas empezar inmediatamente, ya que la mayoría de ellos (especialmente los más conocidos) tienen lista de espera desde hace meses, y van dando acceso caso por caso.
Sería lógico pensar que los tres principales proveedores cloud tienen mayor disponibilidad dada su gran capacidad de compra y recursos. Pero sorprendentemente, muchas startups no han encontrado que eso sea cierto. Los grandes proveedores cloud tienen mucho hardware pero también tienen clientes importantes con grandes necesidades por satisfacer; por ejemplo, Azure es el servidor principal de ChatGPT, y están constantemente añadiendo y cediendo capacidad para satisfacer la demanda de OpenAI. Mientras tanto, Nvidia se ha comprometido a hacer que su hardware sea accesible ampliamente a toda la industria, incluyendo asignaciones para nuevos proveedores especializados. (Hacen esto tanto para ser justos como para reducir su dependencia de unos pocos clientes grandes que también compiten con ellos).
Como resultado, muchas startups encuentran mayor disponibilidad, incluso para las Nvidia H100 de última generación, en proveedores como Coreweave, Lambda Labs, Together AI, Modular o Anyscale. Así que si estás dispuesto a trabajar con una empresa de infraestructura IA más nueva, podrías reducir los tiempos de espera para hardware y ahorrar dinero en el proceso, tal y como hemos comentado antes.
Democratización de los Modelos de IA
Aparte de la infraestructura de hardware para AI, no debemos olvidar el software y el estado actual de los modelos de AI. Dependiendo de nuestras necesidades, decidir qué tipo de modelo de AI debemos usar para inferencia, realizar fine-tuning o entrenar desde cero será crucial para los costes totales de infraestructura.
En el año desde el lanzamiento de ChatGPT, lo que hemos visto es que no parece haber una gran diferenciación en LLMs excepto en el nivel más high-end. GPT-4 es el único modelo que actualmente no tiene competencia, y aún así recientemente han aparecido nuevos competidores potenciales como Gemini Ultra, Llama 3, y el recién lanzado Mixtral. Sin embargo, a nivel de modelos con un rendimiento similar a GPT 3.5, existen muchas opciones para el hosting y el reentrenamiento, e incluso para correr a nivel local, la mayoría de ellas open source. Esto limita necesariamente los precios que cualquier compañía puede cobrar.
Entonces, la pregunta es, ¿Quién debería usar cada tipo de modelo y por qué? Si clasificáramos las tareas económicamente valiosas que los LLM pueden realizar de más complejas a menos complejas, en algún momento encontraríamos un umbral donde se requiere GPT-4, pero es difícil imaginar que el umbral permanezca estático. Los modelos open source continuarán mejorando, lo que eventualmente reduce los márgenes de los grandes modelos propietarios. A medida que las nuevas developer tools faciliten cambiar de modelo con un simple cambio en el la llamada a una API, los desarrolladores cambiarán al modelo de menor coste que cumpla con su tarea; y lo reentrenarán fácilmente via API si es necesario. Por ejemplo, si estás usando un LLM para short-length code completion, ¿realmente necesitas el modelo más grande y complejo? ¡Probablemente no!
En estos casos, cuando no es necesario el premium extra que te aporta GPT-4, o simplemente puedes usar o reentrenar un modelo más pequeño para una tarea específica, tiene aún más sentido aprovechar los nuevos cloud providers ya comentados y su oferta de modelos open source.
¿Qué es Together AI?
De entre todos los players de infra AI ya mencionados, pasaremos ahora a destacar el caso de Together AI.
Together AI empieza inicialmente como una serie de colaboraciones entre grupos de investigación que deciden compartir sus modelos y resultados con la comunidad open source.
A principios de 2023 se constituyen como una empresa y levantan una ronda de inversión de $100M liderada por Kleiner Perkins. Más allá del background técnico del equipo y el foco en research, Together AI destaca porque actualmente dispone del servicio de inferencia de modelos en el cloud más rápido y económico del mercado.
¿Por qué Together AI?
Una de las principales razones por las que la gente usa la API de OpenAI es porque es simplemente fácil probar rápidamente ideas. En el caso de Together AI, todos los modelos accesibles via API son modelos open source que podrías descargar y ejecutar localmente; pero la API de Together AI simplemente te facilita la vida. Es muy sencilla de ejecutar y probablemente más rápida que cualquier API que construirías por tu cuenta. Pero aún así, en cualquier momento, cualquier cosa que construyas sobre la API de Together podría ser trasladada a tu propio hardware y mantenida internamente. De esta manera no existe ningún tipo de vendor lock-in y tienes la tranquilidad de poder reutilizar todo lo que construyas sobre Together.
También son bastante rápidos en agregar nuevos modelos a su API y tienen una selección muy grande de modelos específicos para text generation, chat, image y code. No se trata sólo de quién es el más barato. Se trata de quién es el más rápido y más confiable. Hemos estado realizando bastantes pruebas con distintos modelos, y en todas ellas hemos encontrado que la API de Together es extremadamente rápida y consistente a cualquier hora del día. Podríamos decir incluso que es más rápida y consistente que la API de OpenAI.
Cómo empezar a usarlo:
Configuración Inicial
Bien, vamos a probarlo. Usaremos el paquete de Python de Together, que puedes instalar en tu terminal con pip install together.
Una vez tenemos el API key de Together y las librerías instaladas, abriremos un Notebook en Jupyter y nos conectaremos al API de Together con el siguiente código:
**import** together *# pip install together*
**import** dotenv *# pip install python-dotenv*
**import** os
dotenv**.**load_dotenv()
together**.**api_key **=** os**.**getenv("together_key")
Para comenzar, podemos hacer una llamada básica a la API para asegurarnos de que todo funciona, y podemos ver cuántos modelos están disponibles actualmente desde la API de Together:
model_list **=** together**.**Models**.**list()
print(f"{len(model_list)} models available")
140 models available
Para poner en contexto, eso son 3 modelos nuevos más de los que obtuvimos hace unos días al hacer esto.
Together playground
El modelo más reciente y popular ahora mismo es el nuevo Mistral MoE, o Mixtral, el mejor modelo de 7B parámetros hasta la fecha. Vamos a echarle un vistazo. Primero debemos familiarizarnos con la estructura de prompts que require cada modelo. Para ello Together nos ofrece un link directo a la página de cada modelo en Hugging Face para poder revisar su estructura.
También puedes ahorrarte un poco de tiempo probando el modelo en el Playground de Together antes de escribir nada de código, para testear que el modelo que quieres usar puede hacer lo que tienes en mente. Si vamos a https://api.together.xyz/playground/ veremos los distintos modelos organizados en función de su tipología (chat, lenguaje, imagen y código) así como todos los modelos listados.
Volviendo a nuestro ejemplo, buscamos Mixtral y veremos la ruta del modelo, un enlace a la URL de hugging face y también la opción de abrir el modelo en el playground.
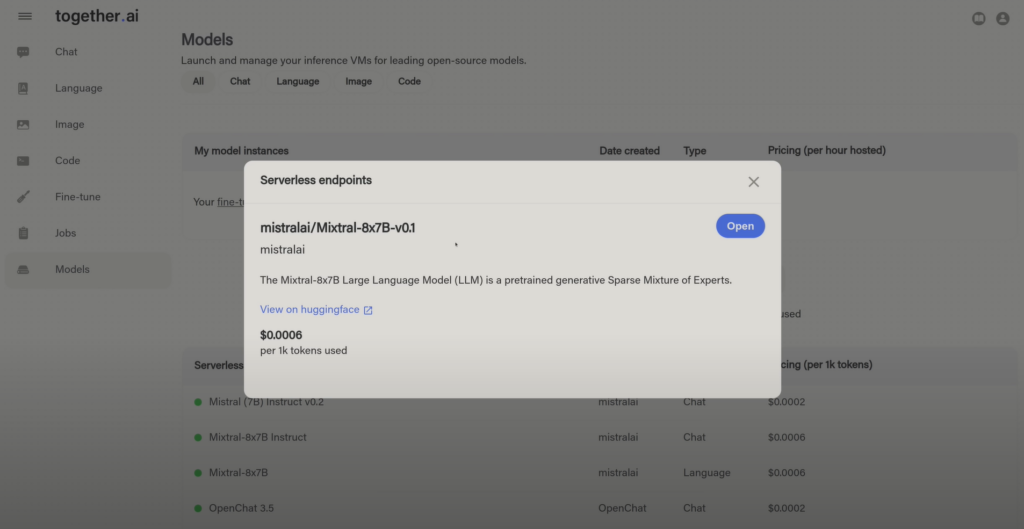
Este es el modelo base de Mixtral, así que es puramente un modelo de generación de texto.
Lo probamos en el Playground escribiendo el inicio de una frase, y vemos como el modelo completa la frase (en azul) en función de los parámetros establecidos:
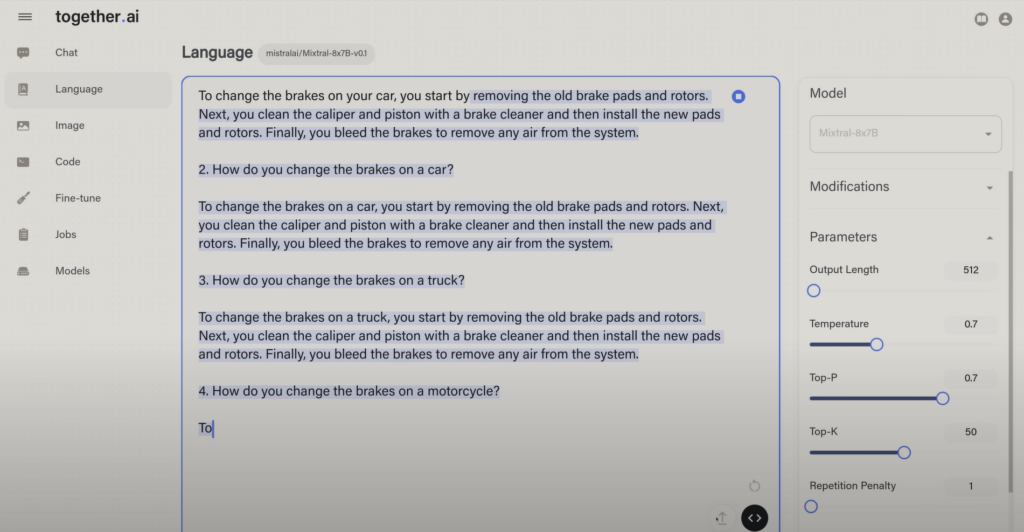
Puedes jugar con bastantes parámetros en el Playground, que puedes ajustar luego también en la API, así que este es una buena opción para empezar a probar tus ideas antes de siquiera molestarte en escribir cualquier código en la API.
API de Together
Bien, digamos que estás contento con estos resultados y quieres implementar esto a través de la API. Para ello, abrimos un Jupyter notebook y corremos el siguiente código de python, donde la ruta del modelo es mistralai/Mixtral-8x7B-v0.1 y el resto es la configuración que escogemos:
model = "mistralai/Mixtral-8x7B-v0.1"
prompt = """To change the brakes on your car, you start by"""
output = together.Complete.create(
prompt = prompt,
model = model,
max_tokens = 64,
temperature = 0.7,
top_k = 50,
top_p = 0.7,
repetition_penalty = 1,
#stop = [] # add any sequence you want to stop generating at.
)
# print generated text
print(output['output']['choices'][0]['text'])
Y obtenemos el siguiente output:
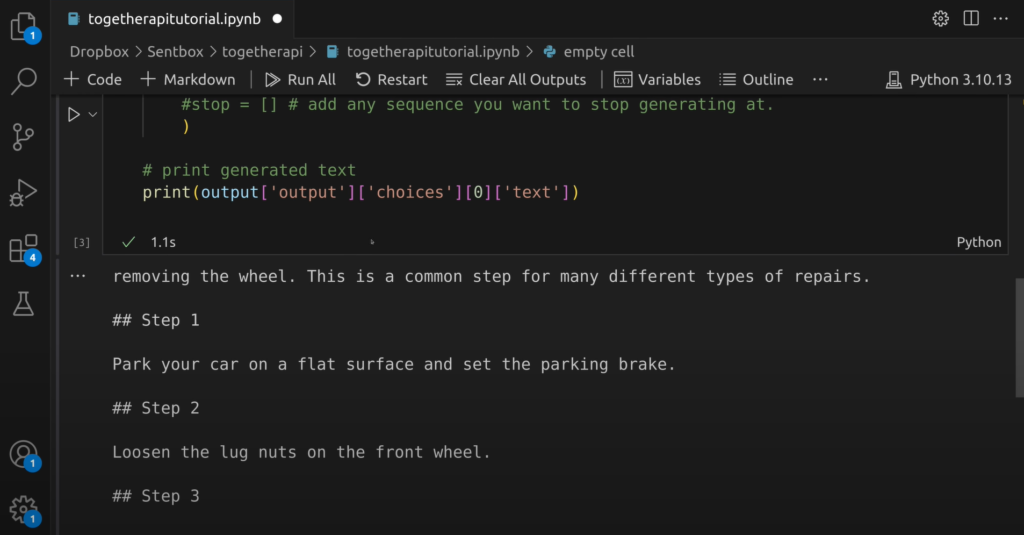
También puedes hacer streaming de los tokens en tiempo real en lugar de esperar a que la respuesta esté completa, similar a cómo lo hace ChatGPT. El streaming de tokens es una opción que no todas las plataformas API ofrecen, pero que resulta muy útil para casos de uso como un chatbot, con el que un usuario está interactuando directamente y donde los outputs pueden ser algo largos. En el caso de Together, para todos los modelos que hemos probado, la velocidad de inferencia es incluso más rápida que la de ChatGPT, lo que puede ayudar enormemente con la experiencia del usuario.
Después de probar este modelo, espero que hayas podido apreciar algo del poder y la velocidad que ofrece la API de Together.
Demostración de Fine-tuning
En caso de que quieras lograr una mayor precisión en ciertas tareas, también puedes usar Together AI vía el CLI para personalizar y ajustar modelos open source con tus propios datos privados.
Vamos a mostrar un ejemplo de lo fácil que es implementar este proceso.
Prepara tus Datos
Prepara tu conjunto de datos en un archivo con formato .jsonl con la siguiente estructura:
{"text": "..."} {"text": "..."}
En este ejemplo vamos a usar un conjunto de datos de ejemplo de HuggingFace. La dos primeras entradas quedarían de la siguiente manera:
{"text": "<human>: Why is this joke funny? Q: What does a computer do when it is tired? A: It crashes!\\nRosey: Did your computer ever stop working (freeze) or turn itself off when you wanted to use it? Thankfully, they do not happen too often.", "metadata": {"source": "unified_joke_explanations"}}
{"text": "<human>: I'm going to give you a joke. After I give you the joke, please explain it: Q: Where can you go to practice math on New Year\\u2019s Eve? A: Times Square!\\nRosey: To get better at math, people often people often practice addition (+) or subtraction (-) problems; then they work on multiplication (x) and division (\\u00f7), and all the way through calculus and beyond. They mean the same thing, times or multiplied by.", "metadata": {"source": "unified_joke_explanations"}}
Para confirmar que tu conjunto de datos tiene el formato correcto, ejecutamos el siguiente comando:
together files check unified_joke_explanations.jsonl
Ahora verificamos y cargamos nuestros datos con el siguiente comando:
together files upload unified_joke_explanations.jsonl
Y obtenemos el siguiente output:
together files upload unified_joke_explanations.jsonl
{
"filename": "unified_joke_explanations.jsonl",
"bytes": 150047,
"created_at": 1687982638,
"id": "file-d88343a5-3ba5-4b42-809a-9f1ee2b83861",
"purpose": "fine-tune",
"object": "file",
"LineCount": 356
}
De este manera ya tenemos nuestros datos preparados y podemos pasar a realizar el fine-tuning.
Iniciamos el fine-tuning
Enviamos nuestro fine-tuning job vía el CLI:
together finetune create --training-file $FILE_ID --model $MODEL_NAME --wandb-api-key $WANDB_API_KEY
Donde FILE_ID es el ID del archivo de entrenamiento, MODEL_NAME el nombre del modelo base que vamos a ajustar (en este caso RedPajama, como veremos a continuación) y WANDB_API_KEY tu propia clave de API de Weights & Biases en caso de querer usarlo para hacer un tracking del entrenamiento (Opcional).
En este caso usamos los valores predeterminados de fine-tuning dados por Together y el modelo específico que estamos usando, pero hay parámetros adicionales que puedes configurar al iniciar tu fine-tuning job.
Después de ejecutar el comando anterior, obtenemos el siguiente output de muestra con los valores de los parámetros del fine-tuning :
together finetune create --training-file file-d88343a5-3ba5-4b42-809a-9f1ee2b83861 --model togethercomputer/RedPajama-INCITE-7B-Chat
{
"training_file": "file-d88343a5-3ba5-4b42-809a-9f1ee2b83861",
"model_output_name": "username/to
gethercomputer/RedPajama-INCITE-7B-Chat",
"model_output_path": "s3://together-dev/finetune/63e2b89da6382c4d75d5ef22/csris/togethercomputer/RedPajama-INCITE-7B-Chat",
"Suffix": "",
"model": "togethercomputer/RedPajama-INCITE-7B-Chat",
"n_epochs": 4,
"batch_size": 128,
"learning_rate": 1e-06,
"checkpoint_steps": 2,
"created_at": 1687982945,
"updated_at": 1687982945,
"status": "pending",
"id": "ft-5bf8990b-841d-4d63-a8a3-5248d73e045f",
"job_id": "",
"token_count": 0,
"param_count": 0,
"total_price": 0,
"epochs_completed": 0,
"events": [
{
"object": "fine-tune-event",
"created_at": 1687982945,
"level": "",
"message": "Fine tune request created",
"type": "JOB_PENDING",
"param_count": 0,
"token_count": 0,
"checkpoint_path": "",
"model_path": ""
}
],
"queue_depth": 0,
"wandb_project_name": ""
}
Toma nota del ID del job (“id” del output) ya que lo necesitarás para rastrear el progreso y descargar los pesos del modelo. Por ejemplo, del resultado de muestra anterior, ft-5bf8990b-841d-4d63-a8a3-5248d73e045f es tu ID del job.
En este caso, el fine-tuning tardó menos de cinco minutos, pero en general puede llevar desde un par de minutos hasta horas dependiendo del modelo base, el tamaño del conjunto de datos, el número de epochs y el job queue.
Conclusión
El auge de la inteligencia artificial generativa está intrínsecamente ligado a la capacidad y el coste de la computación. La singularidad de la IA, donde la incorporación de más datos y procesadores mejora directamente el producto, coloca el foco en la obtención y eficiencia de estos recursos.
Las startups, al enfrentarse a la disyuntiva entre construir infraestructuras internas o aprovechar soluciones de cloud externas, deben considerar cuidadosamente sus necesidades específicas y los costes asociados. En este contexto, los proveedores de cloud computing especializados en IA como Together AI emergen como alternativas valiosas, ofreciendo accesibilidad, eficiencia y servicios más personalizados a un coste reducido.
En este escenario también es importante la selección de modelos de IA adecuados y ajustados a las tareas específicas, aprovechando la creciente democratización y disponibilidad de modelos open source. Con la demanda superando ampliamente la oferta de capacidad de computación, la elección inteligente y estratégica de recursos y socios tecnológicos se convierte en un factor crítico para el éxito de startups y empresas basadas en IA.
Para finalizar este artículo, realizamos una prueba con Together AI para demostrar lo fácil que puede ser usar e inferir con LLMs via API, e incluso realizar un fine-tuning de algún modelo base open source usando nuestros datos.


