Introducción
En el mundo del procesamiento de lenguaje natural (NLP), la arquitectura Transformer ha revolucionado la forma en que entendemos y generamos texto. Esta arquitectura es la base de los LLMs como GPT-4, que son capaces de predecir la próxima palabra en una secuencia de texto con una precisión sorprendente. Sin embargo, para que estos modelos funcionen de manera efectiva, necesitan comprender no solo las palabras, sino también el orden en que aparecen. Aquí es donde entra en juego el positional encoding.
El positional encoding es una técnica utilizada en los modelos Transformer para proporcionar información sobre la posición de cada palabra en una secuencia. A diferencia de los modelos recurrentes, que procesan el texto en orden, palabra por palabra, los Transformers procesan todas las palabras de una vez. Sin una forma de saber la posición de cada palabra, el modelo no podría entender el contexto completo de la oración. En este artículo explicamos cómo funciona el positional encoding y por qué es crucial para los modelos de lenguaje.
¿Cómo intervienen los Positional Encodings en la predicción de palabras?
Para predecir la próxima palabra en una secuencia, los LLMs como GPT-4 utilizan un mecanismo llamado “attention” que evalúa la importancia relativa de las palabras en diferentes posiciones. Los positional encodings se suman a los embeddings de las palabras para proporcionar al modelo información sobre las posiciones relativas de cada palabra en la secuencia. Esto ayuda al modelo a distinguir entre palabras que podrían ser iguales pero están en diferentes lugares, lo cual es crucial para mantener el sentido y la coherencia del texto generado.
Ejemplo: En la oración “El gato duerme en la cama”, el positional encoding permite al modelo saber que “gato” es el sujeto y “cama” es el objeto, y que “duerme” es el verbo que conecta a ambos. Si el modelo solo tuviera los embeddings de las palabras sin información posicional, no podría entender la relación gramatical entre ellas. Así, cuando el modelo necesita predecir la siguiente palabra después de “El gato duerme en la”, utiliza tanto los embeddings de las palabras como los positional encodings para considerar que “cama” es una continuación lógica y gramaticalmente correcta.
Contexto a largo plazo
Los positional encodings también aseguran que el modelo capture dependencias a largo plazo entre palabras. Esto es especialmente importante en oraciones complejas o en párrafos donde el significado de una palabra puede depender de otras palabras muy anteriores en la secuencia. Al tener una representación precisa de las posiciones, el modelo puede mantener una comprensión más coherente y contextual de la información, mejorando así su capacidad para generar texto coherente y relevante.
¿Cómo funciona?
El positional encoding introduce una representación de las posiciones que se suma a los embeddings de palabras o frases. Hay varias formas de implementar esto, pero una de las más comunes es el uso de funciones sinusoidales de diferentes frecuencias. Este enfoque fue propuesto en el trabajo original de Vaswani et al., “Attention is All You Need”. Básicamente, es un un vector que le dice al modelo en qué posición está cada palabra. Veremos un ejemplo más específico a continuación.
Explicación numérica:
Supongamos que estamos trabajando con palabras convertidas a vectores (embeddings) de tamaño 512, que es un tamaño común en muchos modelos. Cada palabra en la oración “El gato duerme” tendrá su propio vector de 512 números. Lo que hace el Positional Encoding es generar otro vector de 512 números para cada posición (posición 0 para “El”, 1 para “gato”, 2 para “duerme”) y sumarlo al vector de la palabra correspondiente.
Fórmulas Matemáticas
Las fórmulas para crear estos vectores de Positional Encoding son las siguientes:
- Para la posición pos y la dimensión i (donde i es par):
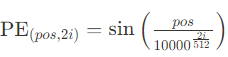
- Para la posición pos y la dimensión i (donde i es impar):
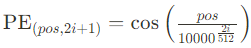
Aquí:
- pos es el índice de la palabra en la oración (0 para “El”, 1 para “gato”, 2 para “duerme”).
- 2i y 2i+1 son índices que recorren las dimensiones del vector.
- 10000 es una constante que ayuda a que las funciones de seno y coseno tengan un rango adecuado.
Ejemplo:
Para simplificar, imagina que estamos usando vectores de tamaño 2 (en lugar de 512):
- Para “El” (posición 0):
- Primer número del vector: sin(0 / 10000^0) = sin(0) = 0
- Segundo número del vector: cos(0 / 10000^0) = cos(0) = 1
- Vector de Positional Encoding: [0, 1]
- Para “gato” (posición 1):
- Primer número del vector: sin(1 / 10000^0) = sin(1)
- Segundo número del vector: cos(1 / 10000^0) = cos(1)
- Vector de Positional Encoding: [sin(1), cos(1)]
¿Cómo se Utiliza?
El vector de Positional Encoding se suma al vector de cada palabra. Así, si “El” tenía originalmente un vector [0.5, 0.8], después de sumar el Positional Encoding (que es [0, 1]), el nuevo vector será [0.5, 1.8]. Esto da al modelo información tanto sobre el contenido de la palabra como su posición en la oración. Para manipular todos estos valores numéricos trabajamos con matrices de vectores a las que llamamos tensores. Lo veremos ahora en un ejemplo.
Implementación y visualización en código
A continuación, se presenta un ejemplo de implementación de positional encoding en PyTorch, similar a cómo se puede usar en un modelo GPT-2:
Paso 1: Inicializamos la matriz de positional encodings (pe) y generamos las posiciones (position)
import torch
import math
# Parámetros del modelo
d_model = 512 # Dimensión del vector de embedding
max_len = 100 # Longitud máxima de la secuencia
pe = torch.zeros(max_len, d_model)
print("Matriz inicial de encodings posicionales (pe):\\n", pe)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
print("Posiciones (position):\\n", position)
Observamos que se generan las siguientes matrices (tensores) de dimensión 512 (dim. embedding) x 100 (long. secuencia):
Output 1:
Inicial matriz de encodings posicionales (pe):
tensor([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...
[0., 0., 0., ..., 0., 0., 0.]])
Output 2:
Posiciones (position):
tensor([[ 0.],
[ 1.],
[ 2.],
...
[99.]])
Paso 2: Aplicamos las funciones seno y coseno a las posiciones
Calculamos el término divisor para aplicar las funciones seno y coseno, y llenamos la matriz pe con los valores calculados.
#Término divisor
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
# Llenamos la matriz pe
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
print("Matriz de encodings posicionales después de aplicar seno y coseno (pe):\\n", pe)
Matriz de encodings posicionales después de aplicar seno y coseno (pe):
tensor([[ 0.0000e+00, 1.0000e+00, 0.0000e+00, ..., 1.0000e+00, 0.0000e+00, 1.0000e+00],
[ 8.4147e-01, 5.4030e-01, 8.2186e-01, ..., 1.0000e+00, 1.0366e-04, 1.0000e+00],
...
Paso 3: Ajustamos las dimensiones de las matrices, y sumamos todo.
Agregamos una dimensión y transponemos la matriz para que coincida con las dimensiones esperadas.
Y finalmente aplicamos un forward pas, es decir, sumamos los encodings posicionales a las entradas.
pe = pe.unsqueeze(0).transpose(0, 1)
x = x + self.pe[:x.size(0), :]
print("Salida del forward pass (x):\\n", x)
Output:
Salida del forward pass (x):
tensor([[[ 0.0000e+00, 1.0000e+00, 0.0000e+00, ..., 1.0000e+00, 0.0000e+00, 1.0000e+00]],
...
Paso 4: Plot del Gráfico
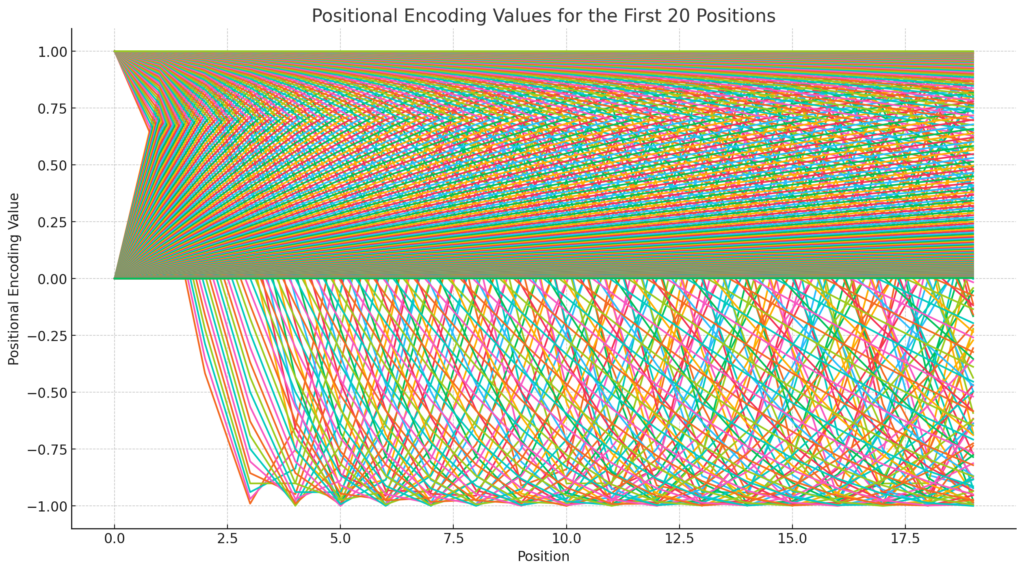
Interpretación del Gráfico
- Patrones Seno y Coseno: Puedes observar que los valores siguen patrones de ondas sinusoidales y cosenoidales. Esto se debe a que, para cada posición, los valores en las dimensiones pares son calculados usando la función seno y en las dimensiones impares usando la función coseno.
- Variación Exponencial: Los valores del positional encoding están limitados entre -1 y 1, así que necesitamos que cambien rápidamente en las dimensiones superiores para que cada posición en una secuencia tenga una representación única y clara. Esto evita que el modelo confunda posiciones diferentes cuando se acumulan muchos valores sobre las acotaciones (en secuencias largas).
- Distribución Regular: Los patrones repetitivos y suaves aseguran que las diferencias relativas entre las posiciones sean claras, permitiendo al modelo inferir la secuencia y el orden de las palabras.
Conclusión
El positional encoding es una técnica esencial en los modelos Transformer, que actúa como un sistema de coordenadas ayudando al modelo a entender el orden de las palabras en una secuencia, combinando esta información con los embeddings de las palabras mismas. Entre sus beneficios, destaca su capacidad para captar el orden de las palabras, ser eficiente sin añadir muchos cálculos adicionales, y generalizar bien a secuencias de diferentes longitudes gracias a las funciones seno y coseno.
Presenta algunas limitaciones como la posible pérdida de precisión con secuencias extremadamente largas debido a las frecuencias fijas usadas y la necesidad de ajustes específicos en algunas aplicaciones. Recientemente, se han propuesto alternativas como los embeddings posicionales aprendidos, que permiten al modelo ajustar la representación de posiciones durante el entrenamiento, y las arquitecturas como T5 que emplean diferentes métodos para incorporar la información posicional. Pero el positional encoding sigue siendo la técnica más ampliamente utilizada a la hora de entrenar Transformers desde cero.

