Qué es Hugging Face

Hugging Face es más que un emoji, es una plataforma open source de ciencia de datos y machine learning. Actúa como un repositorio para expertos y entusiastas del AI, como un GitHub para AI.
En Hugging Face (HF) se pueden encontrar modelos de machine learning y datasets (la muestra de datos que se utiliza para entrenar un modelo).
Originalmente lanzado como una aplicación de chatbot para adolescentes en 2017, Hugging Face ha evolucionado a lo largo de los años para convertirse en un lugar donde puedes: encontrar y utilizar modelos y datasets creados por otras personas; alojar y publicar tus propios modelos; entrenar modelos y colaborar con otras personas; proporciona la infraestructura para ejecutarlo todo, desde la primera línea de código hasta el despliegue en aplicaciones o servicios en vivo.
A finales de 2022 contaba con más de 1M de usuarios semanales. Compañías como Microsoft, Meta y OpenAI han publicado modelos en HF.
En los últimos meses la importancia de HF se ha incrementado por el contexto reflejado en el documento “we have no Moat” de Google. Ninguna gran empresa tecnológica resolverá la AI; será resuelto a través de la colaboración open source. Y eso es lo que permite Hugging Face: proporciona las herramientas que permiten involucrar a tantas personas como sea posible en el desarrollo de las herramientas de inteligencia artificial del futuro.
Modelos
La sección de modelos de HF es un repositorio de modelos. Los modelos se pueden filtrar: i) por tipo de modelo (multimodal, computer visión, …) y por subcategoría; ii) por librería que utilizan (p.e. PyTorch, Flair,…); iii) por dataset utilizado para entrenarlo. Uno de los aspectos importantes de HF es la librería de Transformers.
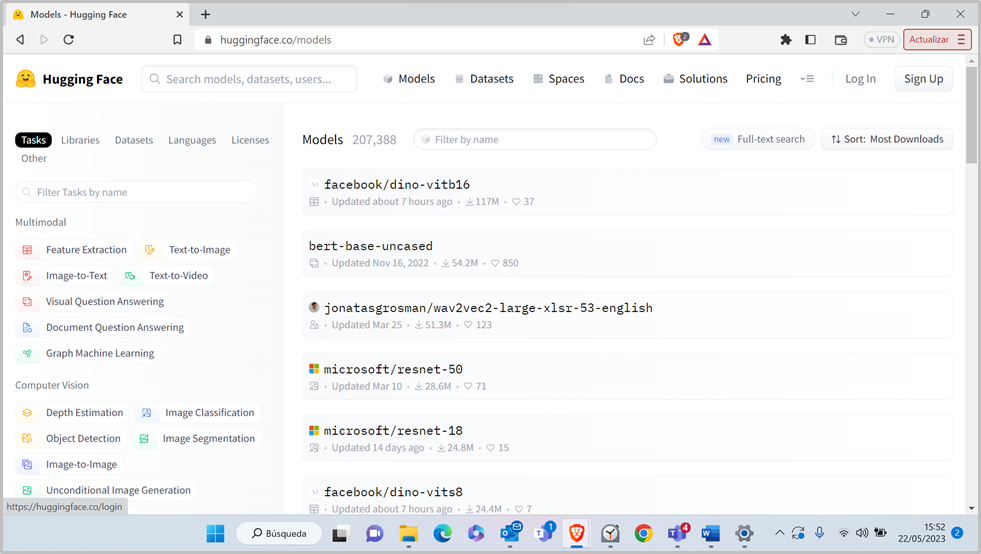
En la imagen mostrada arriba los modelos están ordenados por popularidad descendente, y puede verse que el modelo más popular (facebook/dino-vitb16) ha sido descargado > 110M de veces.
Una de las principales características de Hugging Face es la capacidad de crear tus propios modelos y alojarlos en la plataforma, lo que te permitirá proporcionar más información sobre él, subir todos los archivos necesarios y mantener un seguimiento de las versiones. Puedes controlar si tus modelos son públicos o privados, por lo que puedes decidir cuándo lanzarlos al mundo, o incluso si los lanzarás en absoluto.
También te permite crear discusiones directamente en la página del modelo, lo cual es útil para colaborar con otros y manejar pull requests (cuando otros contribuyentes sugieren actualizaciones al código). Una vez que esté listo para usar, no tienes que alojar el modelo en otra plataforma: puedes ejecutarlo directamente desde Hugging Face, enviar solicitudes y extraer las salidas en cualquier aplicación que estés construyendo.
Si no quieres empezar desde cero, puedes explorar la biblioteca de modelos de Hugging Face. De los más de 200,000 modelos disponibles, podrás trabajar en tareas relacionadas con:
- Natural language processing, incluyendo tareas como traducción, resumen y generación de texto. Estas características son el núcleo de lo que, por ejemplo, ofrece GPT-3 de OpenAI en ChatGPT.
- Audio te permite completar tareas como reconocimiento automático de voz, detección de actividad de voz o texto a voz.
- Computer vision es todo lo que ayuda a los ordenadores a ver el mundo real y entenderlo. Estas tareas incluyen estimación de profundidad, clasificación de imágenes e image-to-image. Estos modelos son clave para los coches autónomos, por ejemplo.
- Los modelos multimodales trabajan con varios tipos de datos (texto, imágenes, audio) y también pueden renderizar varios tipos de salida.
La biblioteca Transformer de Hugging Face te permite usar directamente estos, conectándote a ellos sin necesidad de configurar nada por tu cuenta. También puedes descargar modelos, entrenarlos con tus propios datos o crear rápidamente un Espacio. Es decir, Hugging Face facilita la búsqueda de modelos completos entrenados por terceros, para posteriormente personalizarlos usando datos propios.
Datasets
La sección de Datasets funciona de forma similar a la de modelos; permite filtrar los datasets por criterios como tipo de modelo, tamaño o idioma.
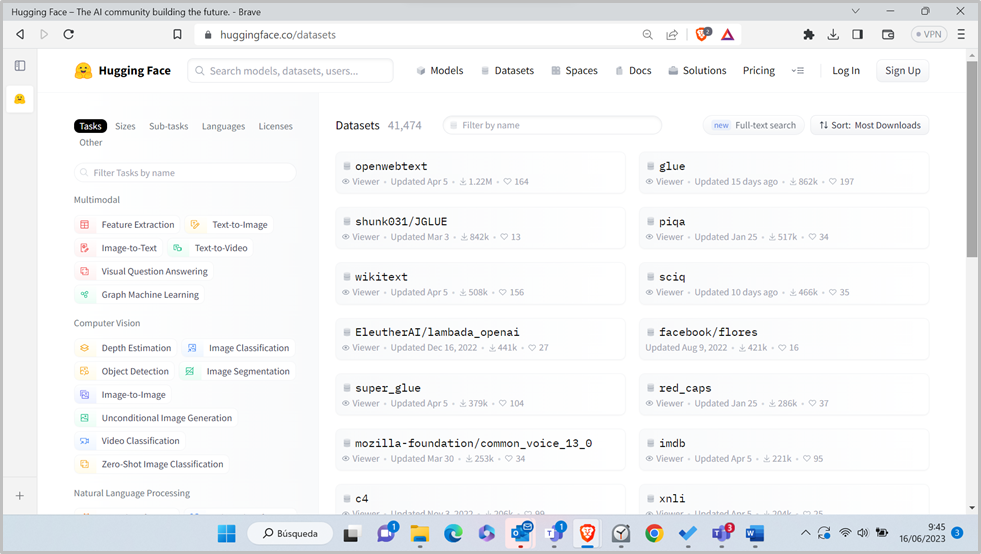
En la imagen anterior puede verse que el dataset más descargado en el último mes (>1,2M de descargas) es el openwebtext, que es un dataset de texto para entrenar modelos de lenguaje. Se trata de una réplica del dataset utilizado por OpenAI para entrenar GPT2. HF permite visualizar una muestra de entradas del dataset:
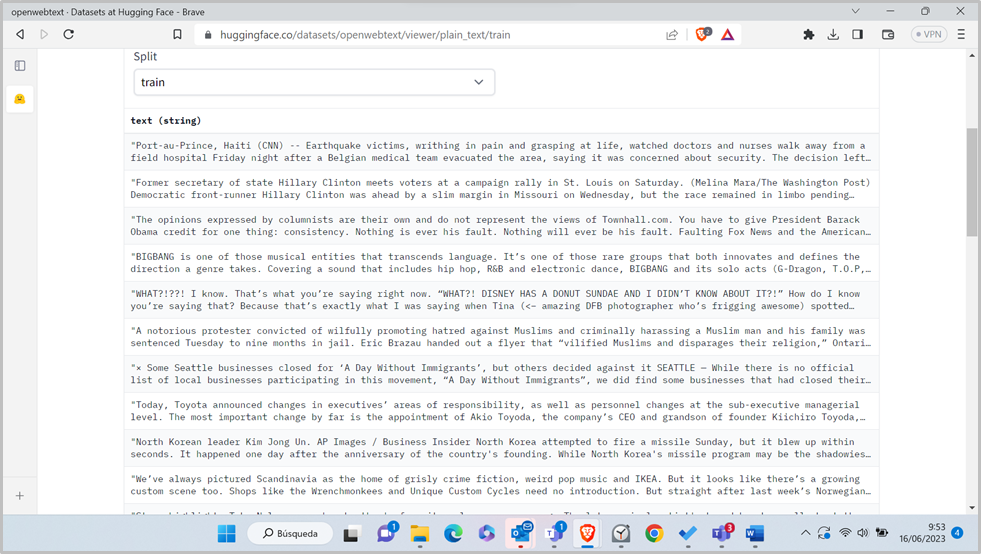
Los datasets parfa fine-tunning o tareas específicas tienen un formato especial, contienen ejemplos conectados con etiquetas. Las etiquetas dan instrucciones al modelo sobre cómo interpretar cada ejemplo. También podemos encontrar datasets más generales sin anotar, y que pueden servir para entrenar un Foundational Model desde cero.
A medida que un modelo se entrena con un dataset, empezará a entender las relaciones que existen entre los ejemplos y las etiquetas, identificará patrones y, en el caso de un ejemplo de modelo de lenguaje, la frecuencia de palabras, letras y estructuras de oraciones. Una vez que se ha entrenado durante un tiempo suficiente, puedes intentar alimentarlo con un prompt que no existe en el dataset. El modelo entonces generará una salida basada en la experiencia que construyó durante la fase de entrenamiento.
El proceso de crear un gran dataset es difícil y requiere mucho tiempo, ya que los datos necesitan ser una representación útil y precisa del mundo real. Si no lo es, es probable que el modelo alucine más a menudo o produzca resultados no deseados. Hugging Face aloja más de 30.000 datasets que puedes alimentar en tus modelos, facilitando el proceso de entrenamiento. Y, como es una comunidad de código abierto, también puedes contribuir con tus propios datasets y explorar nuevos y mejores a medida que se lanzan.
De la misma manera que hay modelos de AI para tareas de procesamiento del lenguaje natural, Computer Vision o audio, HuggingFace también tiene datasets para entrenar estas tareas específicas. El contenido cambia en función de la tarea: el procesamiento del lenguaje natural se apoya en los datos de texto, Computer Vision en las imágenes y el audio en los datos de audio.
¿Cómo son los datasets de Hugging Face? Si das un rápido recorrido por su web, puedes encontrar algunos interesantes:
- wikipedia contiene datos etiquetados de Wikipedia, por lo que puedes entrenar tus modelos en el contenido completo de Wikipedia.
- openai_humaneval contiene código Python escrito a mano por humanos, incluyendo 164 problemas de programación, lo cual es bueno para entrenar modelos de AI para generar código.
- diffusiondb incluye 14 millones de ejemplos de imágenes etiquetadas, ayudando a los modelos de AI de texto a imagen a ser más hábiles en la creación de imágenes a partir de prompts de texto.
Incluso si eres una persona no técnica, es interesante ver cómo se estructura esta data e imaginar cómo un modelo de AI pasaría por ella.
Mostrar tu trabajo en Spaces
Hugging Face te permite alojar tus modelos y explorar datasets para entrenarlos. Pero también tiene un elemento social y de comunidad que te permite llegar a un público más amplio. Para eso sirve Spaces: se crean exhibiciones y demos autocontenidas que ayudan a los usuarios a probar modelos y ver cómo funcionan.
La plataforma proporciona los recursos informáticos básicos para ejecutar la demo (16 GB de RAM, 2 núcleos de CPU y 50 GB de espacio), y puedes actualizar el hardware si quieres que funcione mejor y más rápido. Esto es genial para promocionar tu trabajo y el de tu equipo y atraer a más contribuyentes a tus proyectos.
La mejor parte aquí es que muchos Spaces no requieren ninguna habilidad técnica para usar, por lo que cualquiera puede saltar directamente y usar estos modelos para el trabajo.
Aquí tienes algunos Spaces que puedes probar:
- CLIP Interrogator hace magia de imagen a texto para ayudarte a encontrar el prompt para una imagen que subas. Especialmente útil si quieres mejorar tus habilidades de generación de imágenes recopilando nuevos prompts de imágenes que te gustan.
- Image to music convierte… imagen a música.
- OpenAI’s Whisper puede ser utilizado para reconocimiento de voz, traducción e identificación de idiomas.
Y estos son sólo una muestra. Entrando en Hugging Face Spaces podrás explorar todos los proyectos en los que trabaja la comunidad, pero aviso, es fácil perderse…
Soluciones no code
Si tienes experiencia técnica en el campo de la AI y el machine learning, Hugging Face es una gran caja de herramientas para acelerar el trabajo y la investigación, sin que tengas que preocuparte por el lado del hardware. Pero se requieren habilidades técnicas para exprimir todo lo que Hugging Face ofrece.
Aun así, con su nueva solución AutoTrain, puedes entrenar, evaluar y desplegar automáticamente modelos de Machine Learning de última generación sin la necesidad de programar. AutoTrain encontrará los mejores modelos para tus datos automáticamente, los entrenará y los pondrá a disposición en el Hub de Hugging Face, listos para utilizar.
Otra alternativa sin código es usar Zapier para enviar y recuperar datos de los modelos alojados en Hugging Face, sin la necesidad de programar en absoluto. Por ejemplo, puedes clasificar automáticamente nuevas entradas de Typeform utilizando la clasificación avanzada de texto de Hugging Face; y luego almacenar y organizar los datos clasificados en Google Sheets para un análisis y seguimiento más.


