Introducción
Junto con los modelos fundacionales de lenguaje como ChatGPT, los modelos de generación de imágenes como Midjourney, Stable Difussion y DALL-E han tenido un peso muy importante en la reciente revolución de la IA generativa, creando un profundo impacto en sectores artísticos y creativos. Más allá del impacto de estos modelos a nivel social y de la ética o no ética manera de entrenarlos, vamos a ver en este artículo qué son realmente y a entender cual es la “magia” (o ciencia) creativa detrás de estos.
Modelos clasificadores
Empecemos con un modelo con el que es posible que estemos más familiarizados, un clasificador. Los clasificadores se utilizan ampliamente en data science y si alguna vez has hecho un curso introductorio de Machine Learning seguramente los habrás visto. Intentan asignar etiquetas a los datos.
A continuación, mostramos un clasificador de imágenes, que producirá la etiqueta “pájaro” para la imagen de la izquierda.
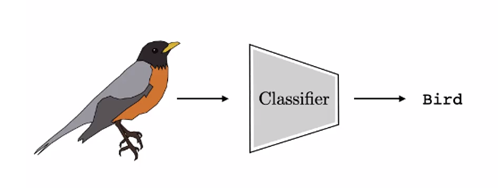
Si comprendes lo que hace un clasificador, es fácil entender lo que hace un modelo generativo, porque un modelo generativo es simplemente lo contrario:
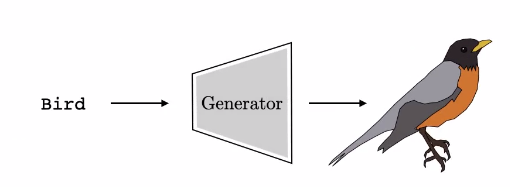
Un generador es lo opuesto a un clasificador. Un modelo generativo toma como entrada alguna descripción de la escena que deseas crear, por ejemplo, la etiqueta “pájaro”, y sintetiza una imagen que coincide con esa entrada. Las cosas son un poco diferentes al operar en esta dirección en comparación con la dirección del clasificador.
¿Cómo sabe el modelo qué pájaro generar? Este petirrojo coincide con la etiqueta “pájaro”, pero también habría sido aceptable generar un tipo diferente de pájaro o un pájaro en una pose diferente.
La forma en que los modelos generativos manejan esta ambigüedad es mediante la aleatorización de la salida, que se logra mediante la inserción de variables aleatorias en el modelo. Puedes pensar en estas variables aleatorias como lanzamientos de dados. Los dados controlan exactamente qué pájaro debes generar, especifican todos los atributos que no están especificados por la etiqueta. En nuestro ejemplo, un lanzamiento de dados resultará en el petirrojo, otro lanzamiento resultará en un pájaro azul y, al lanzar de nuevo, podríamos obtener un loro:
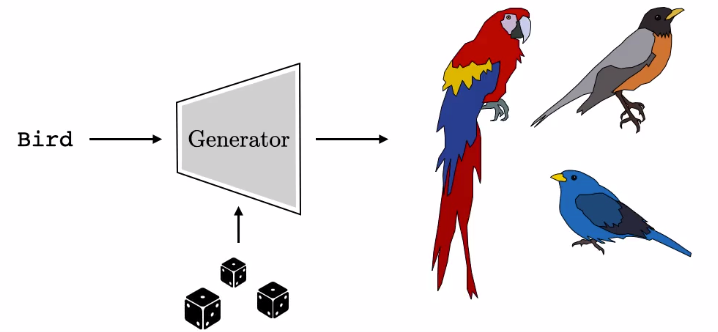
Diferentes lanzamientos de dados resultan en diferentes imágenes que coinciden con la etiqueta “pájaro”.
Variables latentes
El término técnico para los dados es “variables latentes”. Por lo general, tenemos bastantes dados, tal vez más de 100 dados que estamos lanzando. Es decir, tenemos un vector de variables aleatorias (los dados) que son la entrada del generador. Puedes pensar en cada dimensión de este vector como un dado, y cada dado controla un tipo de atributo. La primera dimensión puede controlar el color del pájaro, por lo que al aleatorizar esa dimensión, al lanzar ese dado, cambiará el color del pájaro. Otra dimensión puede controlar el ángulo del pájaro y otra puede controlar su tamaño:
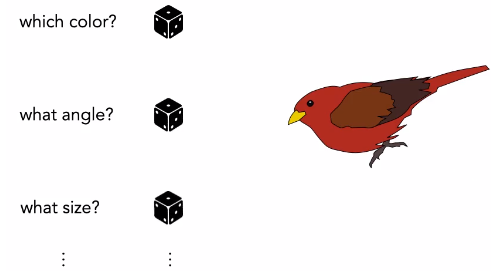
Cada dado de entrada (variable latente) especifica un atributo diferente de la imagen generada.
Pero recuerda que puede haber cientos de estas entradas aleatorias, de modo que la colección de todas ellas puede especificar todas las diferentes propiedades detalladas de cómo se verá el pájaro.
Puedes lanzar estos dados al azar y obtener un pájaro aleatorio, pero resulta que también puedes hacer algo mucho más interesante. Puedes controlar aspectos específicos de la salida del generador fijando la cara del dado con los valores que deseas.
En este caso, los dados se convierten en una especie de dial de control. Puedes girarlos al azar y obtener un pájaro aleatorio o puedes configurarlos manualmente y obtener el pájaro que deseas:
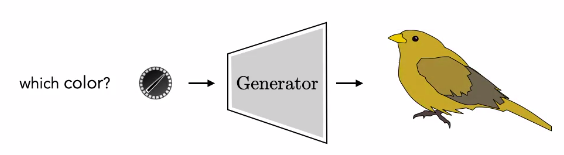
Puedes ajustar la variable aleatoria de entrada que controla el color para encontrar exactamente el color que deseamos. A esto se le llama “model steering”.
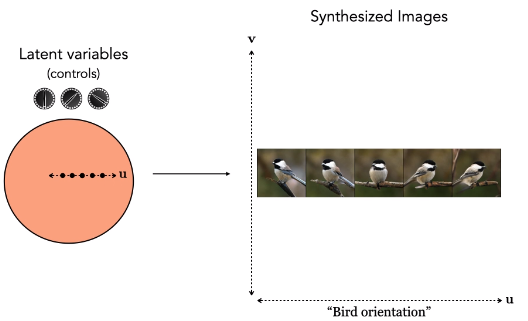
Vamos a enseñar ahora un ejemplo real. A continuación se muestra un modelo generativo, BigGAN, que se lanzó en 2018. Incluso en ese momento, podías hacer las cosas que estamos describiendo. En la parte izquierda tenemos el vector de diales de control que se introducen en el generador, es decir, las variables latentes. El círculo es todo el espacio de posibilidades de estas variables latentes. Si giramos un dial, corresponde a avanzar a lo largo de una dimensión en el espacio latente; en el ejemplo a continuación, resulta que la primera dimensión controla la orientación del pájaro:
Girar otro dial corresponde a avanzar en otra dirección ortogonal en el espacio latente y aquí controla el color de fondo de la foto:
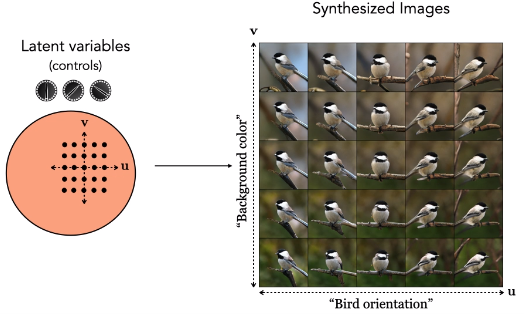
¡Así es como funcionan los generadores de imágenes! La entrada es algún conjunto de controles que se pueden especificar o aleatorizar, y la salida son imágenes.
Entrenamiento de estos modelos
Ahora pasemos a cómo entrenar estos modelos: ¿cómo aprende el generador a mapear desde un vector de entradas aleatorias hasta un conjunto de imágenes de salida que se vean convincentes? Resulta que hay muchas formas y describiremos solo una: los modelos de difusión.
Este enfoque es el más popular en estos momentos, pero el próximo año podría haber un enfoque diferente más popular. Lo importante es tener en cuenta que todos los enfoques tienen más similitudes que diferencias. Todos funcionan en torno al mismo principio básico: generar salidas que se parezcan a los datos de entrenamiento. La idea es mostrar al generador toneladas de ejemplos de cómo se ven las imágenes reales de pájaros y que este aprenda a generar salidas que se parezcan a los ejemplos.
Al igual que los generadores que hemos visto, un modelo de difusión mapea desde variables aleatorias, que ahora llamaremos “ruido”, hasta imágenes. Descubrir cómo crear una imagen a partir de ruido resulta ser realmente difícil. El truco de la difusión es ir en la dirección opuesta y simplemente convertir las imágenes en ruido:
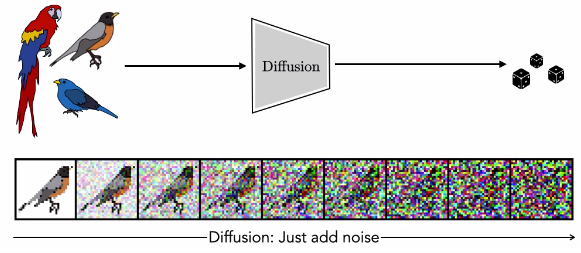
Difussion Models
La difusión es un proceso muy sencillo y funciona igual que el proceso físico de la difusión. Supongamos que estos pájaros no son dibujos, sino globos de animales llenos de gas de colores. Si reviento un globo, el gas se difundirá hacia afuera, perderá su forma y se volverá completamente entrópico; se convertirá en “ruido”. Cada partícula de gas realiza un recorrido aleatorio. Los modelos de difusión hacen esto con una imagen. Cada píxel realiza un recorrido aleatorio.
En cada paso del proceso de difusión, se elige un píxel y se le añade ruido de manera aleatoria. La selección del píxel puede seguir una estrategia determinada, como procesar los píxeles en un orden predefinido (por ejemplo, de izquierda a derecha y de arriba hacia abajo) o de manera completamente aleatoria. La cantidad de ruido añadido en cada píxel también puede ser aleatoria y seguir una distribución específica, como la distribución gaussiana. Esto significa que el ruido añadido puede variar en magnitud y dirección de manera aleatoria en cada paso.
Por lo tanto, con este proceso, una imagen se vuelve más ruidosa a medida que avanzamos, como se muestra en la última fila de la película anterior.
Podemos crear muchas secuencias como esta, cada una mostrando una imagen diferente que paso tras paso va perdiendo estructura y se acaba convirtiendo en ruido. Los modelos de difusión tratan estas secuencias como datos de entrenamiento para aprender el proceso inverso: cómo deshacer el efecto de agregar ruido. ¡Observemos que el proceso inverso es un generador de imágenes! Es un mapeo desde el ruido puro hasta las imágenes. Puedes pensar en el proceso inverso como retroceder en el tiempo y observar cómo todas las partículas de gas se absorben nuevamente en la forma de los globos de animales de donde vinieron. Los modelos de difusión generan imágenes invirtiendo la flecha del tiempo.
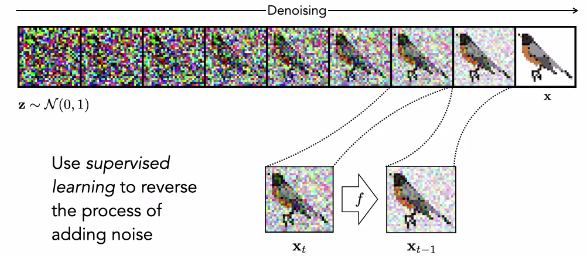
El proceso de difusión inversa mapea el ruido a imágenes y está supervisado por ejemplos del proceso directo.
Una vez que este sistema está completamente entrenado, podemos lanzar los dados, muestreando una nueva imagen de ruido, y luego aplicar el proceso de eliminación de ruido para obtener un pájaro. Si lanzamos los dados nuevamente, obtendremos un ruido diferente que se mapeará en un pájaro diferente.
Así es como funcionan modelos populares como Midjourney, Stable Diffusion o DALL-E. Escribes una frase como “Autorretrato de Salvador Dalí” y luego el modelo muestreará algo de ruido y lo convertirá en imágenes que coincidan con esa oración, utilizando el proceso de difusión inversa. El ruido actúa para especificar todo lo que la entrada de texto no especifica: el ángulo de la cámara, los colores, la expresión facial, el estilo etc.:

¿Por qué coincide la salida con el texto? Ese es el trabajo de una parte separada del modelo. Una estrategia común es simplemente recopilar toneladas de pares {texto, imagen} como datos de entrenamiento, y luego aprender una función que pueda evaluar la alineación texto-imagen a partir de esos datos. El modelo generativo luego se entrena para satisfacer esta función. Pero esto ya lo veremos en otro artículo.
Resumen
En resumen, los generadores de imágenes mapean el ruido a datos, y una forma de entrenar este mapeo es mediante la difusión. Después de que estos modelos se entrenan, el mapeo termina teniendo mucha estructura. En lugar de pensar en la entrada como “ruido”, pensemos en ella como un conjunto grande de diales de control. Estos diales se pueden girar al azar para obtener imágenes aleatorias o se pueden ajustar para crear las imágenes que el usuario desee. Las entradas de texto son solo un conjunto diferente de diales de control, y también se pueden agregar otros tipos de controles, como bocetos, esquemas de diseño o incluso otras imágenes.


