Introducción
Los developers de Machine Learning (ML) se enfrentan en la actualidad a desafíos para desplegar modelos de machine learning similares a los que tenían los desarrolladores de software hace 20 años para desplegar aplicaciones. Según una encuesta realizada a 200 CTOs en el ámbito de machine learning en EEUU, un 85% tenía un presupuesto dedicado a MLOps en 2022, y un 14% adicional esperaba asignar fondos para MLOps en 2023. Aún así, el 71% reconoció que su empresa no lograba utilizar ML para generar ingresos o crear valor comercial como resultado de las dificultades en la implementación de ML a gran escala.
Hemos visto en los últimos años una fuerte inversión en el desarrollo de modelos de AI, pero con este crecimiento han surgido nuevos desafíos y la necesidad de nuevas herramientas, que no han podido seguir el mismo ritmo de evolución. La adopción de AI se ha duplicado desde 2017 hasta 2022, pero un porcentaje significativo de los proyectos de data science no llegan a producción, y los proyectos que sí lo hacen tardan 7 meses de media en desplegarse. Los desarrolladores de software tienen toda una cadena de herramientas para desplegar y reutilizar código, y hoy en día los equipos de ingeniería de software que adoptan prácticas de DevOps pueden desplegar 208 veces más más rápido. Los developers de ML necesitan soluciones similares.
En este panorama, Weights and Biases (W&B) ha surgido como una de las soluciones más consolidadas para los practicantes de ML. Dada la necesidad de crear una herramienta para desplegar y gestionar modelos de ML con éxito, W&B ha construido una plataforma que proporciona varias herramientas para el seguimiento de experimentos, visualización de rendimiento y ajuste de hiperparámetros (explicado más abajo). Más allá de adaptar los principios de DevOps al mundo ML (i.e., MLOps), W&B sigue la tendencia de herramientas colaborativas vista en otras categorías.
Historia y contexto
Cuando escribes código directamente (no vía AI/ML), puedes leer y entender lo que hace cada parte. Puedes crear versiones y mapear diferencias entre ellas. El debugging nunca es fácil, pero contamos con setenta años de experiencia en debugging y hemos construido una increíble variedad de herramientas y mejores prácticas para hacerlo bien. Con el machine learning, estamos en una situación distinta. En lugar de programar el ordenador directamente, escribimos código que guía al ordenador para crear un modelo que genera instrucciones para el ordenador. No podemos modificar el modelo directamente o incluso entender fácilmente cómo hace lo que hace. Las diferencias entre versiones del modelo no tienen sentido para los humanos: si cambiamos el modelo, aunque sea ligeramente, cada bit en el modelo probablemente será diferente. Y todos los problemas que siempre ha arrastrado el machine learning, están magnificados con el deep learning. En definitiva, machine learning es un nuevo paradigma donde es más difícil entender e interpretar los cambios en un modelo; de ahí que Andrej Karpathy describiera el machine learning como una nueva forma de programación que necesita un IDE reinventado.
Viendo esta necesidad, Lukas Biewald y Chris Van Pelt decidieron fundar Weights & Biases (W&B) en 2017. Los dos habían fundado previamente y pasado casi una década construyendo Crowdflower juntos (ahora conocido como Figure Eight), que proporciona datos de entrenamiento anotados de alta calidad para machine learning.
Biewald empezó en el mundo del machine learning en 2002, cuando construyó su primer algoritmo de ML en una clase de Stanford, y para 2007 estaba convencido de que el mayor problema en machine learning era el acceso a datos de entrenamiento, lo que le llevó a fundar Figure Eight. Después de trabajar en Figure Eight durante una década y vender la compañía a Appen por $300M, Biewald trabajó en OpenAI. Mientras estaba allí, descubrió que las herramientas para el desarrollo de modelos hacían difícil modificar modelos directamente o incluso entender lo que los modelos estaban haciendo.
Biewald pidió a Van Pelt ayuda para construir algunas herramientas para el desarrollo de modelos, y Van Pelt creó un prototipo de lo que se convertiría en Weights & Biases. Mientras que en 2007 pensaban que el acceso a datos de entrenamiento era el mayor freno en el progreso del machine learning, en 2017 tenían claro que el principal bloqueo ya no era ese, sino más bien una falta de herramientas específicas y mejores prácticas para gestionar un estilo de programación completamente nuevo. Decidieron entonces empezar Weights & Biases para resolver ese problema.
El nombre de la compañía se refiere al objetivo típico de entrenar un modelo: encontrar un conjunto de “pesos y sesgo” que creen un modelo que tenga una pérdida baja, es decir, minimizar la diferencia entre los valores predichos y los valores reales.
¿Qué es y por qué es relevante?
W&B busca ser una solución integral para proyectos de Machine Learning, agilizando todo el proceso desde el desarrollo hasta el despliegue. La plataforma ofrece distintas soluciones como seguimiento de experimentos (registro de cualquier cambio en cualquier modelo), visualización y monitoreo de modelos (permitiendo a los usuarios entender mejor el comportamiento y rendimiento del modelo), colaboración, optimización de hiperparámetros y comparación entre modelos. En abril de 2023, W&B lanzó un nuevo producto dirigido específicamente al desarrollo de Large Language Models (LLMs), entrando así en el subcampo de LLMOps.
Desarrollar y desplegar un modelo de ML es un proceso complejo. De la misma manera que un cocinero, al desarrollar y hacer una nueva receta, necesita llevar un registro de todos los ingredientes que está utilizando, los pasos que está tomando y cómo está quedando la comida, los practicantes de ML necesitan llevar un registro de los parámetros y de cómo se desempeña el modelo. Estos elementos son clave para construir un buen modelo.
¿Qué problemas nos resuelve W&B?
Seguimiento de Experimentos
A diferencia del software tradicional, en el mundo de data science es mucho más común tener un número alto de versiones o variaciones de un mismo modelo cuando está siendo desarrollado y testeado, haciendo difícil llevar un registro de todas las iteraciones. W&B ofrece un producto de seguimiento de experimentos, que busca ser “el sistema de registro para el entrenamiento de modelos”. Esto permite a los developers de ML, con solo 5 líneas de código, implementar rápidamente un registro de experimentos que les permite rastrear, comparar y visualizar distintas versiones de su modelo de ML. Los inputs del modelo y los hiperparámetros pueden ser fácilmente guardados, y el rendimiento de cualquier modelo puede ser graficado contra cualquier otro modelo, permitiendo una fácil comparación, como vemos a continuación:
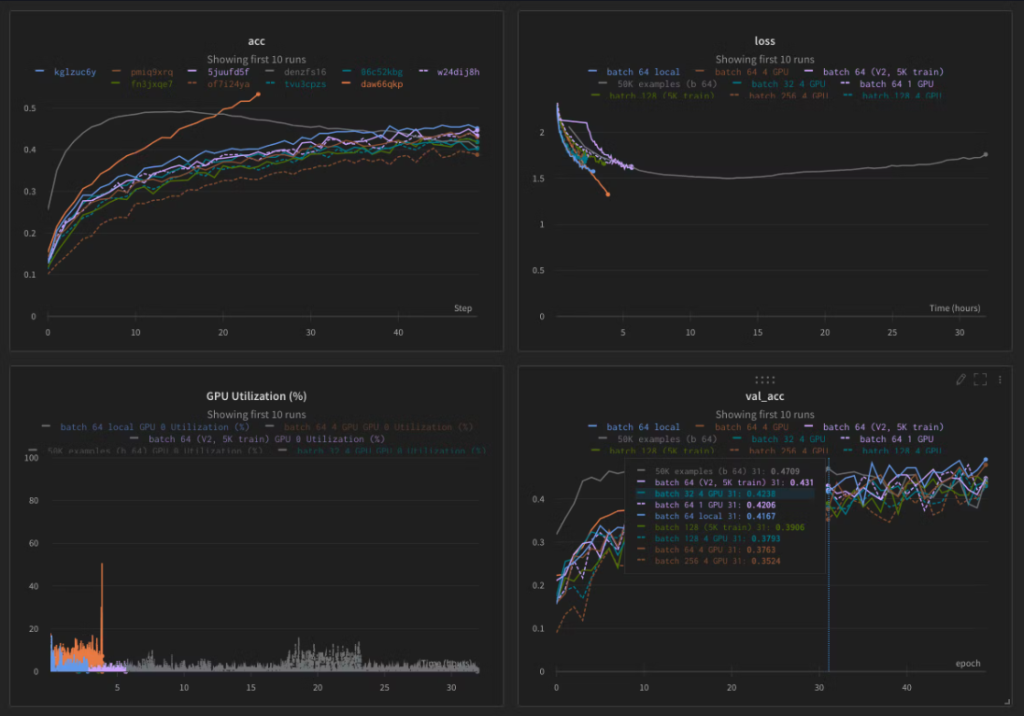
El seguimiento de experimentos de W&B también permite un fácil control de versiones, es decir, la modificación de parámetros dentro de un mismo experimento, permitiendo a los usuarios encontrar y volver a ejecutar rápidamente puntos de control de modelos anteriores. El uso de CPU y GPU también puede ser monitoreado para identificar cuellos de botella en el entrenamiento y evitar el desperdicio de recursos costosos. Los usuarios también pueden versionar automáticamente conjuntos de datos registrados o modificados, en función de las particiones realizadas (training/testing), y los problemas de duplicación los gestiona W&B de forma automática.
Registro de Modelos
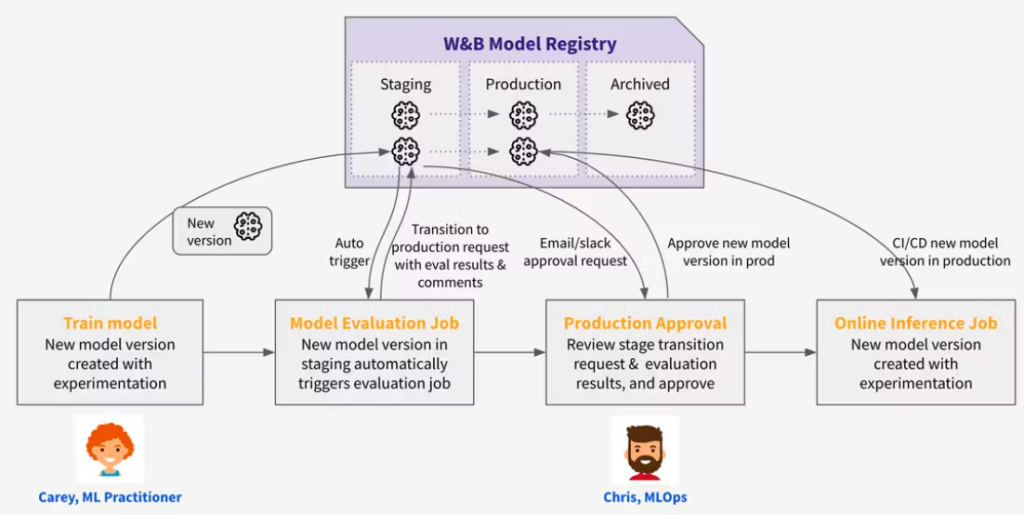
W&B ofrece un producto de “registro de modelos y gestión del ciclo de vida” que permite a los usuarios colaborar y rastrear versiones de modelos en miles de proyectos, millones de experimentos y cientos de miembros de un equipo. Busca ser un lugar central desde el cual uno pueda “gestionar todas las versiones de modelos a través de cada etapa del ciclo de vida, desde el desarrollo hasta el deployment y la producción.”
El registro de modelos proporciona a los usuarios una fuente central de verdad: deja claro qué modelo está en producción y cómo comparan los nuevos modelos candidatos. También permite a los usuarios determinar fácilmente en qué conjuntos de datos se entrenó un modelo dado. Además, proporciona soluciones para Model CI/CD y puede entrenar y reevaluar automáticamente modelos para mantener frescos los modelos de producción de un equipo. El historial de cualquier actualización de modelo también puede ser fácilmente auditado. W&B está diseñada para complementar y mejorar el proceso de entrenamiento de modelos en Python y PyTorch u otros frameworks de machine learning como TensorFlow, Keras, etc. No los reemplaza, sino que actúa como una capa complementaria que facilita la experimentación y la iteración rápida.
Ajuste de hiperparámetros
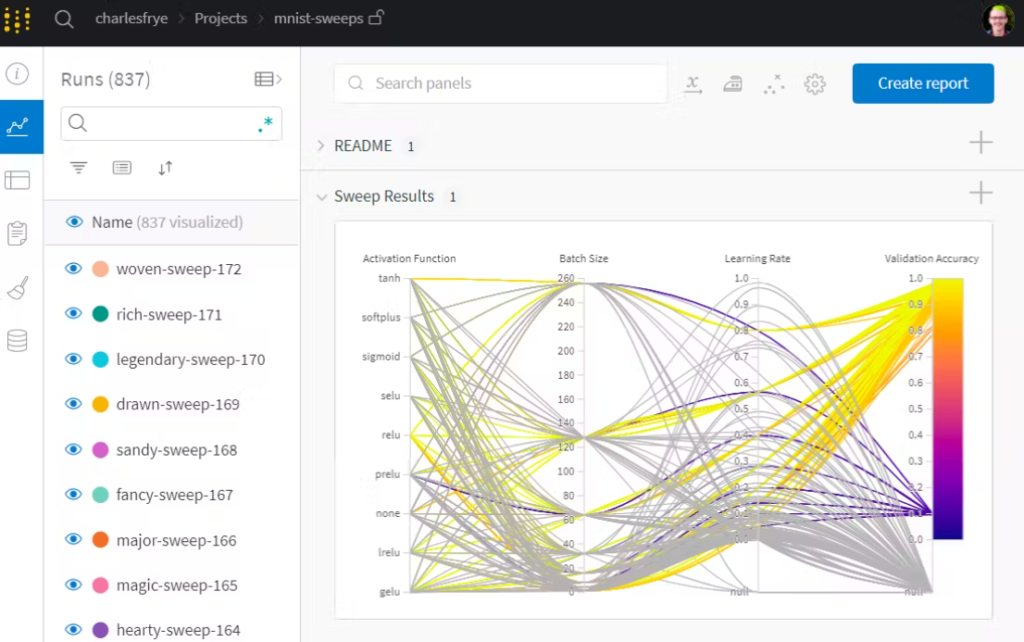
Sweeps es un producto ofrecido por W&B que ayuda a automatizar y optimizar el proceso de ajuste de hiperparámetros para modelos de machine learning.
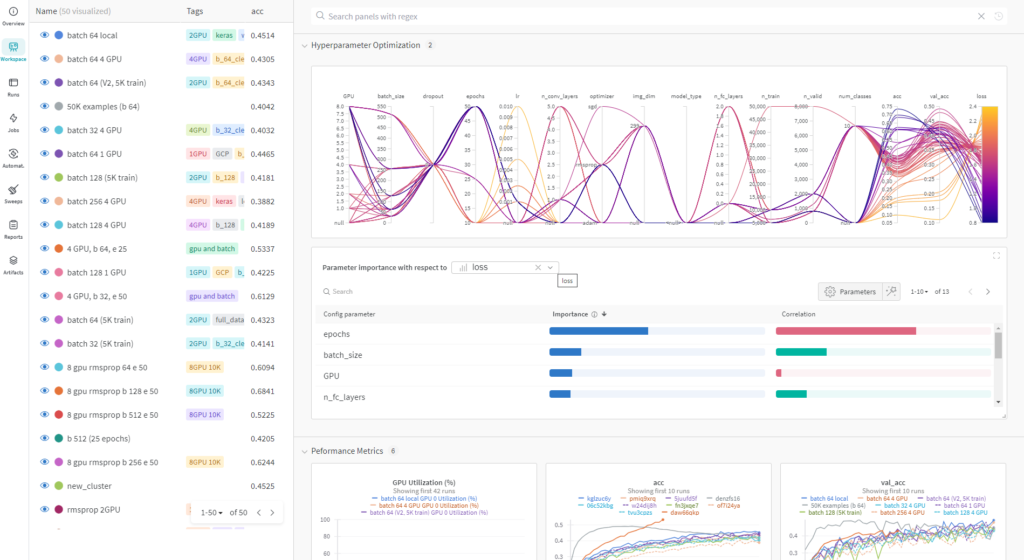
Los hiperparámetros son configuraciones que los developers de ML necesitan ajustar antes de entrenar un modelo. Controlan varios aspectos del proceso de entrenamiento e influyen significativamente en el rendimiento y comportamiento del modelo. Los hiperparámetros pueden incluir aspectos como la tasa de aprendizaje, el tamaño del modelo, el número de capas en una red neuronal y la regularización, entre otras. Estas configuraciones interactúan de maneras complejas, y ajustarlas manualmente puede ser un proceso lento y propenso a errores o sesgos humanos. Como tales, son clave para desarrollar cualquier modelo de ML. El dashboard de W&B que ofrece esta funcionalidad se ve de la siguiente manera:
Configuración de hardware
El producto Launch de W&B facilita el entrenamiento de modelos de ML. Permite iniciar estos entrenamientos en una variedad de entornos informáticos, desde el propio ordenador personal hasta configuraciones más potentes como clústeres de ordenadores. Launch permite a los usuarios conectarse y utilizar recursos externos, como unidades de procesamiento gráfico (GPUs) más rápidas y clústeres de ordenadores, para mejorar la velocidad y eficiencia de su trabajo en machine learning.
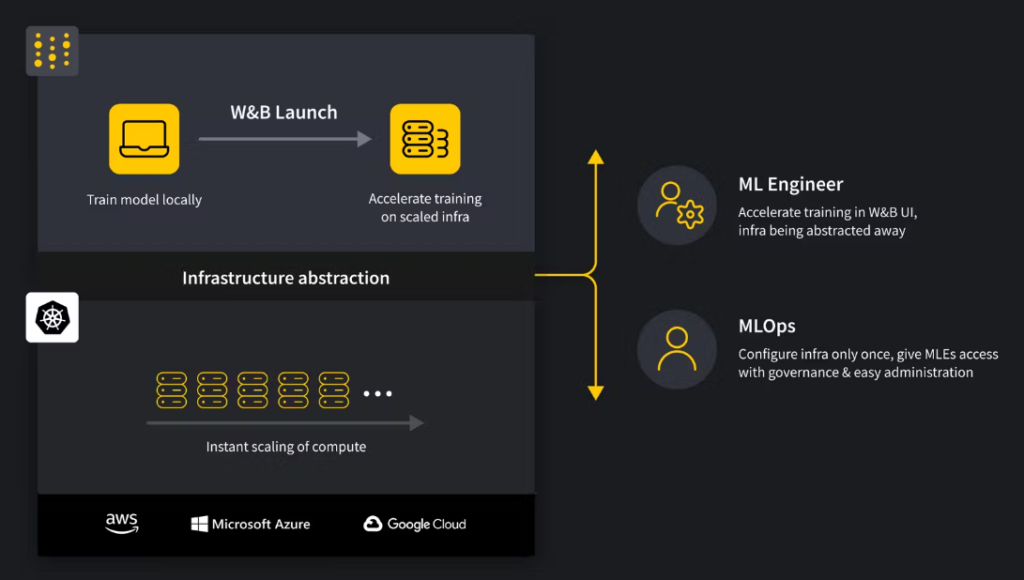
Los profesionales de ML pueden acceder a los recursos informáticos que requieren sin tener que lidiar con las complejidades técnicas de configurar y gestionar esos recursos por sí mismos. Por otro lado, MLOps (el lado operativo del machine learning) puede vigilar y monitorear cómo se están utilizando estos recursos para asegurar que todo funcione sin problemas. También permite a los usuarios configurar procesos automatizados que prueben y evalúen continuamente sus modelos de machine learning. Launch busca tender un puente entre los profesionales de ML y MLOps, al proporcionar una interfaz compartida, elimina las barreras entre ambos grupos y les permite trabajar juntos de manera más efectiva.
En general, Launch ayuda los usuarios para acortar el tiempo que se tarda en mover modelos del desarrollo a su uso en aplicaciones del mundo real.
Quién debería empezar a usarlo
W&B es relevante tanto para equipos grandes de ML en empresas como para equipos pequeños o desarrolladores individuales. Dentro de las empresas, W&B es usado por equipos de data science, developers de machine learning e ingenieros de datos, ya que proporciona una plataforma colaborativa para el seguimiento de experimentos y permite la colaboración entre los miembros del equipo.
Para desarrolladores individuales que trabajan con ML, W&B también es una herramienta útil. Los investigadores individuales pueden aprovechar sus características de seguimiento de experimentos para mantener un registro de su trabajo, mejorando la transparencia y reproducibilidad. Los freelancers y consultores pueden usar W&B para gestionar y mostrar de manera efectiva sus proyectos a los clientes.
Los grandes clientes empresariales a menudo exigen un alto nivel de seguridad, por lo que W&B se integra tanto con proveedores de servidores en la nube como en servidores locales . La plataforma ofrece una gestión robusta de identidad y acceso, monitoreo de seguridad e integraciones con servicios de seguridad en la nube.
Cómo empezar a usarlo
Podemos empezar a usar W&B en pocos minutos. Solo necesitamos crear una cuenta, abrir un notebook en Google Colab y seguir los siguientes pasos:
1. Antes de comenzar, necesitamos crear una cuenta e instalar W&B: Regístrate para obtener una cuenta gratuita en https://wandb.ai/site y luego inicia sesión en tu cuenta de wandb para obtener tu API key. Ahora, abrimos un notebook en Google Colab e instalamos la librería wandb en un entorno de Python 3 usando pip:
!pip install wandb
2. Iniciamos sesión en W&B: A continuación, importamos el SDK de Python de W&B e iniciamos sesión con este comando:
wandb.login()
Proporciona tu API key cuando se te solicite.
3. Pasamos a la acción: Inicializamos un objeto Run de W&B en nuestro notebook con el método wandb.init() y pasamos un diccionario al parámetro config con pares clave-valor de nombres de hiperparámetros y valores:
run = wandb.init(
project="my-awesome-project", # Establece el proyecto donde se registrará esta ejecución
config={ # Rastrea hiperparámetros y metadatos de ejecución
"learning_rate": 0.01,
"epochs": 10,
},
)
Un objeto Run es el bloque básico de construcción de W&B. Básicamente, cada vez que ejecutas un script de entrenamiento y utilizas la librería de W&B (wandb), se crea un nuevo run que encapsula toda la información y métricas generadas durante esa sesión de entrenamiento.
Integramos W&B con nuestro modelo
Un script para entrenar un modelo tendría la estructura del siguiente ejemplo. El código resaltado en rojo muestra el código específico de W&B. La parte que no está en rojo modeliza dos variables de entrenamiento usando valores aleatorios para luego poder graficarlas con W&B:
# train.py
import wandb
import random # para el script de demostración
wandb.login()
epochs = 10
lr = 0.01
run = wandb.init(
project="my-awesome-project", # Establece el proyecto donde se registrará esta ejecución
config={ # Rastrea hiperparámetros y metadatos de ejecución
"learning_rate": lr,
"epochs": epochs,
},
)
offset = random.random() / 5
print(f"lr: {lr}")
# simulando una ejecución de entrenamiento
for epoch in range(2, epochs):
acc = 1 - 2**-epoch - random.random() / epoch - offset
loss = 2**-epoch + random.random() / epoch + offset
print(f"epoch={epoch}, accuracy={acc}, loss={loss}")
wandb.log({"accuracy": acc, "loss": loss})
offsetes un valor aleatorio que se usa para agregar variabilidad a los resultados simulados.- Se itera a través de las épocas del entrenamiento (desde la época 2 hasta
epochs). - En cada iteración, se calculan valores aleatorios para la precisión (
acc) y la pérdida (loss). - Se imprimen estos valores y se registran en Weights & Biases usando
wandb.log().
Este script no está entrenando un modelo de machine learning real, sino que simula las variables accuracy y loss de forma aleatoria para luego poderlas graficar y mostrar los resultados como ejemplo en el dashboard de W&B. En caso entrenar un modelo real, simplemente sustituiríamos nuestro código en esa parte.
Para integrar W&B con nuestro ML framework de preferencia (i.e., PyTorch, Keras, TensorFlow) seguiremos siempre una estructura similar al siguiente ejemplo, respetando los comandos específicos para cada integración, los cuales podemos encontrar en W&B Integrations.
Una vez ejecutado este script, el último paso sería entrar en nuestro usuario de W&B (https://wandb.ai/home) para ver cómo las métricas que hemos registrado en nuestro script (accuracy y loss) han mejorado en cada paso del entrenamiento del modelo, tal y como vemos a continuación:
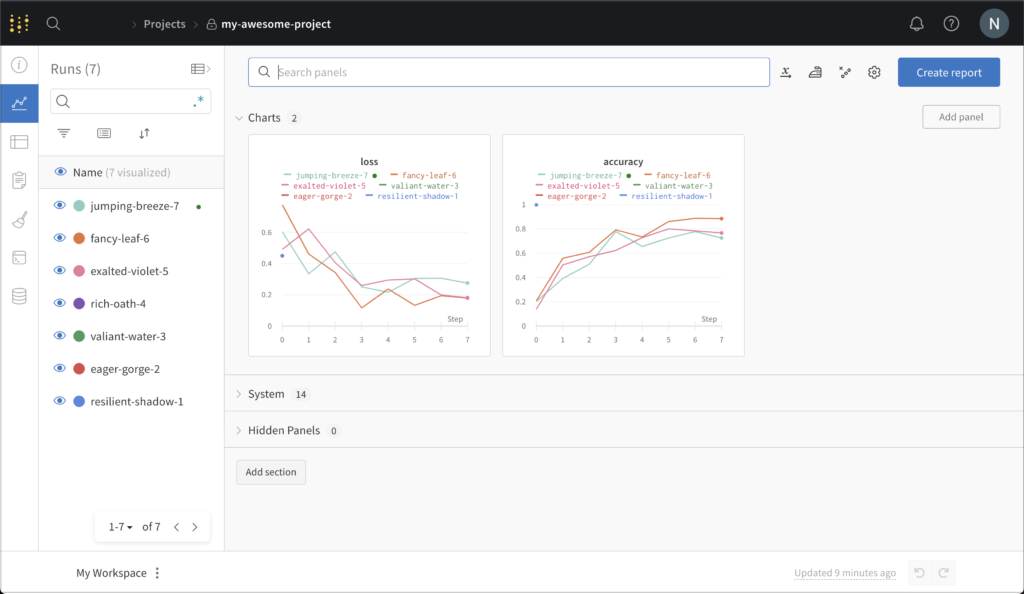
La imagen muestra la pérdida y precisión que se rastrea cada vez que ejecutamos el script anterior. Cada objeto de ejecución que se crea se muestra en la columna de Runs (los nombres se genera aleatoriamente).
En el caso de un entrenamiento real con un número variables más elevado, obtendríamos un dashboard como el siguiente:
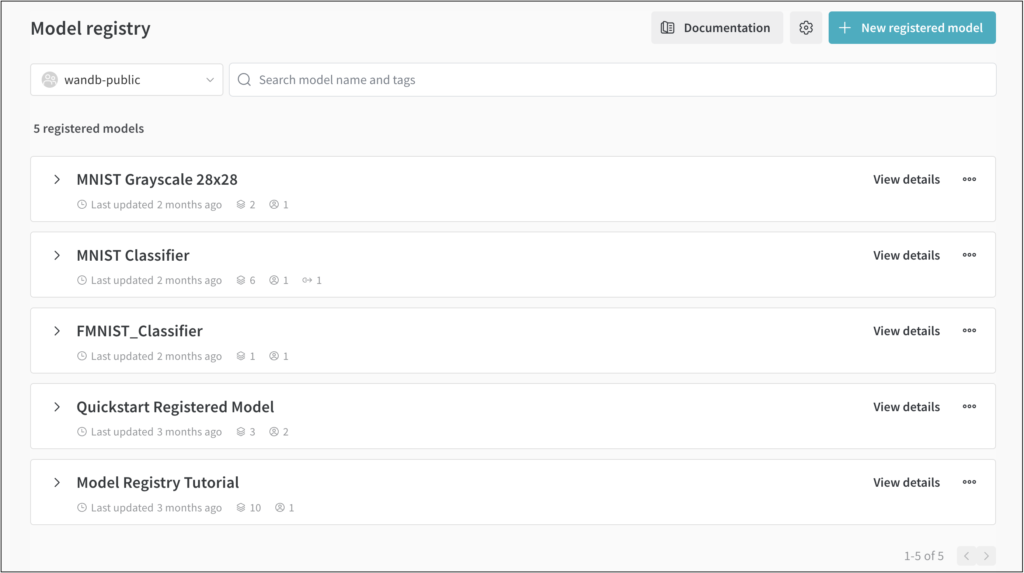
Y en caso de trabajar con varios modelos o versiones distintas de un mismo modelo, podemos entrar en el panel de Model registry y observar todos los modelos registrados, tal y como vemos a continuación:
Con este sencillo ejemplo, hemos podido ver las principales funcionalidades de W&B y como acceder a ellas. En caso de querer adentrarse más y explorar el resto de funcionalidades, la documentación de W&B es el mejor recurso disponible y explica todo de forma muy clara.
Conclusión
A lo largo de este artículo, hemos explorado cómo los desafíos en la implementación y gestión de proyectos de machine learning han llevado a un aumento en la adopción de prácticas de MLOps. A pesar del crecimiento en el desarrollo de modelos de AI y un incremento en la asignación de presupuestos para MLOps, muchas empresas todavía enfrentan dificultades significativas en generar valor comercial a escala a partir de sus inversiones en ML.
Weights & Biases (W&B) emerge como una solución end-to-end que ofrece distintas herramientas para el seguimiento y despliegue de modelos. La plataforma se alinea con la tendencia hacia herramientas colaborativas y está diseñada para atacar los desafíos específicos que presenta el machine learning, que son distintos a los de la programación tradicional. En definitiva, la adopción de herramientas como W&B puede ser crucial para superar las barreras operativas y estratégicas en el mundo del machine learning, permitiendo a las empresas y profesionales maximizar el valor y el impacto de sus iniciativas de ML.


